
精度の高い機械学習を実現するためには、質・量の伴ったデータセットの準備が欠かせません。今回はデータセットとはどういうもので、役割や種類、データセットの作り方、代表的なデータセットの一覧までをわかりやすく紹介します。
機械学習のデータセットとは?その重要性
機械学習は、ある程度まとまったデータを基にして、決められた法則で学習し、予測や推論を行っていきます。この、まとまったデータのことを「データセット」といいます。
データセットの内容は、音声認識や画像認識、自然言語処理など、分析したいデータによってさまざまです。その内容が質・量ともに揃っていれば、機械学習の精度が高まり、汎用的に使えるものとなるでしょう。
一方で、データセット自体が不適切なものであった場合、実行後のアウトプットが意に反するものとなってしまいます。そのようなアウトプットに基づき意思決定をした場合、重大な損失を生む可能性も考えられるでしょう。
機械学習を行う際には、その目的や背景、仮説などを十分検討した上で、どのような内容のデータセットが必要か考えることが重要です。
機械学習で使われるデータセットと使われ方
機械学習で使われるデータセットは、次の3種類に分かれます。それぞれどのような目的で使われるのかを確認しましょう。
トレーニングセット
トレーニングセットは、機械学習モデルを構築するために用いられる学習用のデータセットです。最初に使用され且つ、最も規模が大きいという特徴があります。訓練用データ、学習用データとも言われます。
バリデーションセット
バリデーションセットは、トレーニングセットで訓練したあと、「ハイパーパラメーター」をチューニングするために利用します。ハイパーパラメーターとは、機械学習アルゴリズムの挙動を制御するパラメーター (変数)のことです。ハイパーパラメーターの設定によって、モデルの性能が大きく変わるため、適切に調整することが重要になります。
トレーニングセットによってハイパーパラメーターを訓練したあと、バリデーションセットを利用し、その上でパフォーマンスが優れているものを選択し、採用します。
テストセット
テストセットとは、構築した機械学習モデルの精度を確認するためのデータセットで、最終段階にのみ使われるのが一般的です。正確なテストを行うために、トレーニングセットで使用していないデータを用いましょう。評価用データ、検証用データとも呼ばれます。
データセットの入手方法
次に、データセットはどうやって揃えられるのか、入手方法を3パターンご紹介します。
独自で集める方法
データセットは、自身でアンケート調査を活用するなど独自でデータを収集することが可能です。その場合、工数はかかりますが、費用を抑えられるメリットがあります。
独自でデータを集めた際には、扱いやすいようデータを整理することが大切です。具体的には、以下のような点に注意して収集したデータをまとめるとよいでしょう。
- Excelは、確認や修正がしやすいCSVファイル形式で作成する
- データを入力する際は、サンプルを縦、特徴量を横に記載するなどシンプルに整理する
- データの読み込みができるよう、セル結合は使わない
外注して集める方法
自分で集めることが難しい場合は、外部に依頼してデータを収集することもできます。例えば、クラウドソーシングを活用する方法や、信ぴょう性の高いデータを提供してくれる専門会社もあるので、検討してみるとよいでしょう。データ収集を外注すれば、独自で集める場合に比べて社内工数を大幅に削減できます。
一方で、その分費用がかかることを理解しておきましょう。また、外注であっても、学習データとして使用する際には、データの中身が適切か十分確認することが大切です。
オープンデータセットを利用する方法
インターネット上で公開されている「オープンデータ」の活用も方法の一つです。政府や研究機関などが公開しています。動画データや画像データ、テキストデータなど、Web上にはさまざまな種類のデータが公開されています。
オープンデータは整ったデータを得られることも多く、これらを活用すれば社内工数を削減できるでしょう。ただし、データの使用に費用がかかったり、商用利用ができなかったりするケースもあります。事前に、利用可否の確認を忘れないようにしましょう。
最後の章では、Web上に公開されているオープンデータ/サイトを25個ご紹介します。
データセットの作り方
データセットを機械学習で使える状態にするにはどのようにすればよいのでしょうか。データセットの作り方はデータのタイプ(画像か、動画か、音声か、時系列データかなど)によって様々ですがここからは、作り方の手順を解説します。
①目的・課題・仮説の明確化
いきなりデータセットの作成に取り掛かる前に、適切なデータセットを用意するために機械学習で解決したい課題は何か、実施する目的を明確にしましょう。
また、機械学習によって得たデータを分析・検証できるように事前に仮説を立てておくことも必要です。具体的な課題や目的を考えておくことで、どのようなデータセットを準備すべきかが明確になります。
②データの収集
モデルの課題を明確にしたら、データを収集する作業に移ります。前述したように、収集するデータの質と量で、機械学習の精度は大きく変わります。また、教師あり学習か、教師なし学習かでデータの収集方法が変わります。
オーバーフィッティング
収集するデータの量が足りない場合、「オーバーフィッティング」という現象が起きるリスクがあります。オーバーフィッティングとは、学習データには適合するものの、新たなデータを予測できないモデルが出来てしまうこと。オーバーフィッティングを防ぐためには、少しずつデータ量を増やすことが有効です。
アノテーション
教師あり学習の場合、データを収集したら「アノテーション」を行います。アノテーションとは、日本語に直訳すると「注釈」を意味する言葉です。機械学習におけるアノテーションは、機械学習のモデルに学習させる各データに教師データ(=正解ラベル)を付与することを指します。
アノテーションを行うことで、データのルールやパターンを精密に覚えられ、正しいモデルを判断できるようになります。アノテーションをするソフトやサービスもあるので活用を検討してみましょう。
教師なし学習の場合、アノテーションは不要ですので次のステップに進みます。
データ整形時の注意点「整然データ」
データを作る際に意識すべきポイントとして、整然データを意識しましょう。
整然データとは、以下4つの条件に合致したデータのことです。
- 1つのセルには1つのデータ(値)が存在する
- 1つの列は1つの変数をあらわす
- 1つの行は1つの観測をあらわす
- 個々の観測ユニットの類型が1つの表をなす
この条件に当てはまっていないデータは雑然データと言い機械学習に使う構造化データのデータセットには向きません。
例えば、以下の図は都道府県・市区町村別の人口データです。国勢調査データなどは左の雑然データのように全国(合計)と都道府県と市区町村の変数が同じ列に記載されていることがあります。
こういうデータは見やすさの観点では良い場合もありますが、機械学習など分析に使うデータベースとしてはふさわしくありません。
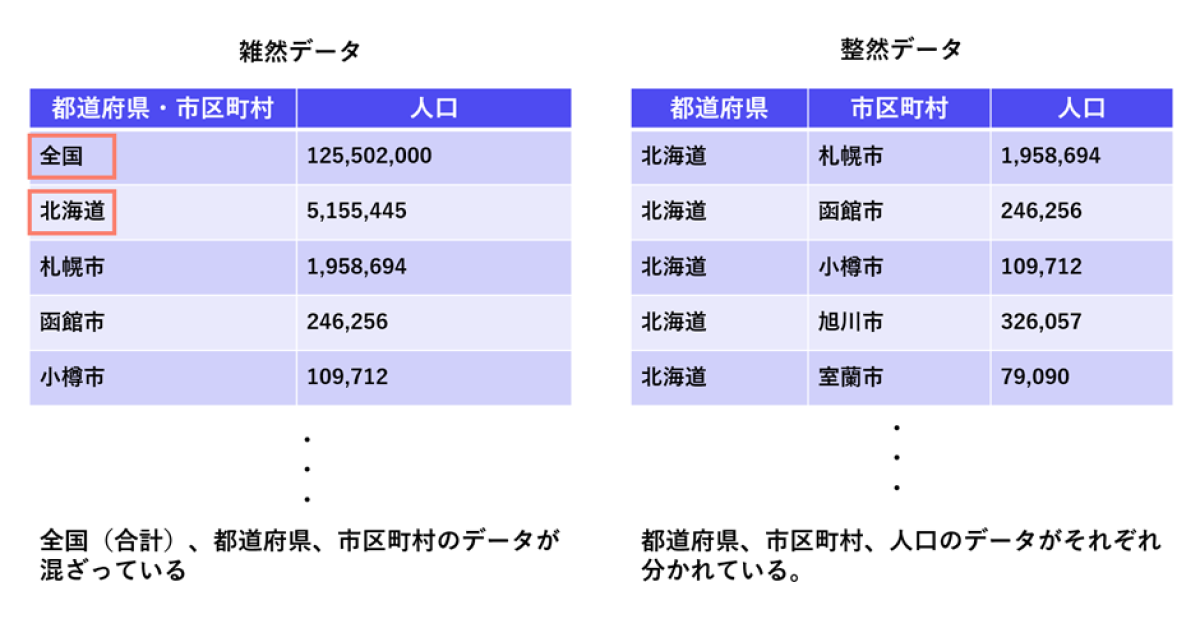
右の整然データのように都道府県と市区町村の列を分け、全国(合計)の値は含めないようにしましょう。
データの取得と保有、活用方法などについてはこちらの「DXで重要なデータの活用方法とポイントを解説!データを活用する職種やデータ一覧も紹介」の記事でもご紹介しておりますので、併せてご覧ください。
③データの加工
最後に、コンピューターが読み取りやすいように、収集したデータを加工処理します。加工が不十分だと、コンピューターが上手く読み込めない可能性もあるので、後述するデータセット作成時の注意点に気を付けながら、質の高いデータセットを作り上げましょう。
データの加工には「欠損値の処理」「ダミー変数化」「外れ値除去」などがあります。
欠損値の処理
データには何らかの理由で記録されていない値が含まれます。欠損値があると統計的分析ができない場合があるため処理をする必要があります。処理の方法としては欠損値を含むサンプルの削除や、欠損値を統計学的アプローチで予測し補完する方法などがあります。
ダミー数変化
ダミー数変化とは、数字で表せないデータを数字で表すことです。これにより統計解析が可能になります。例えば「はい、いいえ」のデータをそれぞれ「1,0」に置き換えたり、「男、女」のデータをそれぞれ「1,0」に置き換えたりします。
外れ値・異常値の除去
外れ値とは、他の計測値から極端に離れた値を意味します。異常値とは入力ミスや計測不備などが原因で極端な値、もしくはあり得ない値を取っているものを指します。
外れ値については、分析により何かしらの示唆を得られることもあるため除去しない場合もあります。除去する場合は外れ値と判断した理由を明確にできるようにしましょう。
除去した後の対応は欠損値の処理と同様です。
④トレーニングセットとテストセットにデータを分割する
データの加工まで終わったら、そのデータを学習用に使うトレーニングセットと、学習済みモデルの精度をテストするテストセットに分割しましょう。
比率はだいたい「トレーニングセット:テストセット=7:3~8:2」程度が良いでしょう。
生成AIの全社導入はすでに約6割に拡大!生成AIの利用実態調査レポート〜2024年12月版〜
2022年、Chat GPTが一般リリースして2年が経ち、生成AIの業務における活用レベルや組織における利用率は確実に向上してきています。
組織としての生成AIの利用が本格化し、これまで以上に成功事例を聞くようになった今、企業の生成AI活用はどう変化しているのでしょうか。
本レポートは2023年4月から継続的に実施しており、5回目となる調査レポートです。262社310人を対象におこなった最新の「生成AIの利用実態調査」を大公開しているため、ぜひご参考にください。
- 企業全体での活用からRAG(データ連携)の取り組み状況
- 社員がどの程度生成AIを活用しているのか、その実態
- さらに注目が集まる「AIエージェント」に関する関心や活用状況 など
データセット作成時の注意点
データセットを作るときに意識したいポイントを4つ解説します。
データセットの被覆性
様々な状況で高い精度を出す学習モデルを作るためにも、データは想定されるものを網羅的に集める必要があります。こうした状況の抜け漏れがなく、十分な量のデータが与えられていることをデータセットの被覆性といいます。
データが足りないと、機械学習において適切に推論できません。学習した知識を別の領域の学習に適用させる「転移学習」を利用すれば、データ数の少ない場合でも精度を上げられますが、それでは不十分な場合もあります。どのようなデータが必要なのか検討し、網羅的にデータを収集しましょう。
参考:『機械学習品質マネジメントガイドライン 第3版』国立研究開発法人産業技術総合研究所
データセットの均一性
「データセットの被覆性」の対となる考え方として併せて覚えておきたいのが「データセットの均一性」です。データセット内の様々なケースの発生頻度がデータ全体で均一であるとする考え方です。データを大量に用意できない場合、「Aのデータは1万個あるが、Bのデータは100個しかない」という状況になると、機械学習の精度に大きな影響があります。
また、前述した「データセットの被覆性」と「データセットの均一性」のバランスは実際の応用や解析したい対象の特性によって考慮する必要があります。
一般的に機械学習の訓練用データセットは均一であった方が予測精度は高くなるとされますが、頻度が稀なケースについて十分なデータ量を確保しつつ、均一性も保とうとすると膨大なデータ量が必要になります。その場合は稀なケースを重点的に訓練するといったことが考えられます。
参考:『機械学習品質マネジメントガイドライン 第3版』国立研究開発法人産業技術総合研究所
バイアスのないデータに整える
収集したデータ自体に特定のバイアスがかからないようにすることも気をつけたいポイントです。例えば、天気を予測するAIを作りたい場合、データセットの天気データが山の上だけで計測されたデータだと、平地の天気予報において精度の低いAIができてしまう可能性があります。そうしたバイアスがかからないようにデータ取得時の方法や環境も意識しましょう。
ノイズのないデータに整える
収集したデータは、ノイズを除いたデータセットにする必要があります。例えば、以下のような場合は、その要因を確認した上で適宜除外する必要があります。前述した「欠損値の処理」「外れ値・異常値の処理」と同様の対応をしましょう。
- 数値が入るはずのデータに文字列が入っている
- 重さのデータにおいて、単位が「kg」が正なのに、「ポンド」が入っている
- 気温のデータで100℃など、通常では考えられないデータが入っている
著作権法
法律の知識を持ち合わせておくと、データセットの準備もスムーズに行えるでしょう。日本の著作権法では、機械学習のために第三者が著作権を持つデータを元に学習させ、学習済みモデルを公開しても問題ないとされています。例えば、画像認識AIを開発するためにネット上の画像を利用したい場合、その画像の著作者に確認を取る必要はありません。
ただし、第三十条の四では「著作権者の利益を不当に害することとなる場合は、この限りでない。」と記載されています。不安な場合は、法務担当者に相談することをおすすめします。
機械学習におすすめのデータセットサイト25選
最後に、機械学習に使えるデータセットを公開しているサイトを25サイト紹介していきます。サイトによってデータの形式やライセンス、その後の機械学習への使いやすさなど特徴があるため使いやすいサイトを見つけてみてください。
データセット検索サイト
機械学習に使えるデータセットを検索できるサイトがあるのでご紹介します。欲しいデータセットがなかなか見つからない場合は検索サイトで検索してみましょう。
Dataset Search
Dataset Searchは、Googleが提供している「データセットに特化した検索サービス」です。2020年に正式版がリリースされ、最終更新日、ダウンロード形式、ライセンス、トピック、無料かどうかでフィルタリングができます。
似たサービスでGoogle scholarがありますがこちらは学術文献のデータベースになっています。
Paper with code
Paper with codeはコードが GitHub で公開されているものを対象にコードや関連論文、データセットが公開されています。コードもセットのため、簡単にコードを試してみたい場合などに役立ちます。
Kaggle
企業や政府などの組織と、機械学習・データサイエンスに携わる人々をつなげるプラットフォームです。企業や研究機関などが公開している何万ものデータセットをダウンロードできます。
CSV、JSON、SQLite、BigQueryなどのファイルタイプがあり、カテゴリとしてはスポーツ、医療、ソフトウェア、食べ物、旅行などに関してのデータセットがあります。
データセット総合掲載サイト
多くの種類のデータセットを掲載しているサイトも存在します。
TensorFlow Datasets
TensorFlow Datasets は、TensorFlow や他の Python ML フレームワーク(JAX など)で使用できるデータセットのコレクションです。Catalogから好きなデータセットを選び簡単なコードを実行するとデータセットをダウンロードできます。
HuggingFace Dataset
HuggingFace Datasetはデータセットを検索してダウンロードできるだけでなく、前処理も可能です。また、データセットのカテゴリごとの活用方法のガイドや、TensorFlow やPyTorchで活用する時のガイドも掲載しているためダウンロードしたデータセットをすぐに活用したい方にお勧めです。
UCI Machine Learning Repository
カリフォルニア大学のアーバイン校が管理&公開している機械学習データセットのリポジトリです。大学が公開しているため信頼性も高く研究者の間でも有名で、更新頻度が高く、2023年1月時点で612個のデータセットが公開されています。
検索性にも優れていてデータタイプ別(画像、表形式、文章、時系列データ、多変量データなど)や分野別(仕事、コンピュータサイエンス、エンジニアリング、ゲーム、法、生命科学、物理化学、社会科学など)、タスク別(分類、回帰、クラスタリングなど)などの観点で検索ができます。
参考:『UCI Machine Learning Repository』
DATA GO JP
デジタル庁が整備、運営するオープンデータに係る情報ポータルサイトです。政府や独立行政法人、地方公共団体などが保有する多様で膨大な公共データが無料で公開されています。
Google Cloud 一般公開データセット
BigQueryに保存され、「Google Cloud 一般公開データセットプログラム」を通じて一般提供されているデータセットです。気象や経済、医療や小売りといったさまざまな分野のデータセットを利用できます。
画像のおすすめデータセット
画像のデータセットを掲載しているサイトを紹介します。
The CIFAR-10 dataset
The CIFAR-10 datasetは「飛行機」「自動車」「船」「トラック」などの乗り物や、「鳥」「猫」「鹿」「犬」「カエル」「馬」などの動物の10クラス×6,000個=60,000個のカラー画像データがあります。50,000個がトレーニングセットで1,000個がテストセットです。
Google Open Images
Google Open Imagesは約900万枚の画像に物体検知用の境界ボックスやセグメンテーション用のマスクなどの様々なアノテーションがされたデータをダウンロードできるサイトです。
ダウンロードできるデータは、190万枚の画像に600個、合計1600万個の境界ボックスが付与されていたり、画像の内容を表す注釈(「ギターを弾く女性」「テーブルの上のビール」など)が330万個のオブジェクトに付与されていたり、280万個のオブジェクトインスタンスのセグメンテーションマスクが付与されていたりと、画像分類、オブジェクト検出、四角関係検出などに役立つデータセットがダウンロードできます。
動画のおすすめデータセット
YouTube-8M Dataset
Googleの研究チームが公開している動画データセットです。YouTubeから取得した動画にアノテーションが付与された動画データをダウンロードできます。約610万個、合計35万時間分の動画が公開されています。
YouTube-BoundingBoxes Dataset
YouTube-BoundingBoxes は、Googleが公開しているデータセットで、公開されているYouTubeの動画から約24万件の動画が公開されています。1050万の人間による注釈、560万の境界ボックスが付与されており、ラベリングの精度は95%を公式サイトに記載されています。
参考:『YouTube-BoundingBoxes Dataset』
テキスト・文章データのおすすめデータセット
日本語対訳データ
日本語を対象とする機械翻訳システムの構築に利用できる言語資源のリストです。対訳文からなるコーパスで、統計的機械翻訳システムの学習に活用できます。
Google Books
Google Books とはGoogleが公開する書籍のテキストデータ検索サービスです。Google がスキャンした紙の書籍が全文検索でき、著作権があるものは一部、著作権が切れている書籍は無料で全文表示されます。
Wiki-40Bデータセット
Wiki-40Bデータセットは、英語や日本語を含む40以上の言語のWikipediaデータを前処理して作られた言語モデル用データセットです。Wikipediaには本文以外に参考文献や注釈のリストなどの不要なテキストデータも含まれているためそれらを除外する前処理が大変でした。それらの前処理をしたデータです。
TensorFlow Datasetsで簡単に利用できます。
音声データのおすすめデータセット
音声資源コンソーシアム
音声資源コンソーシアム(SRC)は、国立情報学研究所が提供している音声情報処理に関する研究開発を推進することを目的とした音声コーパス(データベース)です。様々な機関が公開したデータセットをまとめており、それぞれのページでオンライン申請をすることでデータを取得できます。
AudioSet (Google)
AudioSetとはGoogleが提供する大規模なサウンドデータです。YouTubeの動画を基にした210万の注釈付き動画データがあります。人間の音、動物の音、物音、音楽、自然の音など様々なカテゴリの音データが手に入ります。
MIMII
MIMIIは日立製作所が公開した産業機械の正常・異常音のデータセットです。バルブ、ポンプ、ファン、スライドレールなど、4種類の産業機械から生成される正常音・異常音が含まれています。
工場のスマートファクトリー化を推進している方にはお勧めのデータセットです。
ToyADMOS
ToyADMOSはNTT研究所で作成された異常音検知用のデータセットです。約540時間の通常の機械操作音と、12,000 を超える異常音のサンプルの機械操作音データセットであり、おもちゃの車、おもちゃのコンベア、おもちゃの列車の音なども収録されています。
関連論文:『A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection』
医療関連データのおすすめデータセット
HealthData.gov
HealthData.govとは、米国保健福祉省(U.S. Department of Health & Human Service)が公開している保健関連のデータの共有サイトです。2023年2月時点で4,522件のデータセットが登録されています。医療機関や政府機関において得られた臨床データや全国的な医療サービス、最新の医薬品や医療科学の情報、コミュニティ健康活動などのデータセットが登録されています。
CheXpert
CheXpertは、胸部X線の大規模データセットを公開しています。2002年10月から2017年7月の間にスタンフォード病院の入院患者、外来患者65,240人の224,316枚の胸部 X 線写真で構成されています。データは13の病気+異常無しの計14つに分類され、それぞれ放射線科医が陽性か陰性、または不確実とラベル付けしています。
金融関連データのおすすめデータセット
Quandl
Quandlは投資家向けに公開している金融・経済に関連するデータセットを公開しています。多くのデータは無料でダウンロード可能で様々な国の数百万の財務データをPythonで数行のコードを書くだけで利用可能です。日本のデータもあります。
世界中の投資家やアナリストに利用されています。
World Bank Open Data
World Bank Open Dataは世界中の金融・経済関連の調査研究データが公開されています。世界銀行という貧困削減や開発支援を目的とし世界120か国以上で1万人以上の職員が業務にあたっている機関が公開しているデータベースサイトです。日本のデータもあります。
大企業の生成AI導入・活用の実態と、投資失敗を防ぐ3つの秘訣とは?
生成AIを「全社レベルで導入済み」と回答した企業は、すでに全体の6割を超えています。
一方で、導入しただけでは成果に結びつかず、現場での活用が進まなかったり、過剰投資に終わったりするケースも少なくありません。
本資料では、262社・310名(大企業を中心とする)への調査結果をもとに、導入率や活用部門、定量的な効果はもちろん、多くの企業が直面した失敗の原因を「自社開発」「SaaS導入」それぞれの観点から徹底分析しています。
さらに、生成AI投資の失敗を乗り越えるための“3つのステップ”も解説。AIエージェント時代を見据え、これからの戦略設計に役立つ実践的なヒントが詰まっています。
自社の生成AI活用を推進したい方は、ぜひダウンロードしてご活用ください。
まとめ
機械学習におけるデータセットの意味や役割、作り方などを簡単に説明しました。適切なデータセットの作成は、精度の高い機械学習を実現する上で欠かせません。データセットの入手方法は複数あるので、工数とコストを比較して検討するのがおすすめです。データセットが入手できたら、実際に機械学習に活用してみましょう。