
ChatGPTのベースとなった「Transformer」とは?その凄さと今後の可能性をわかりやすく解説!
リリースからわずか2ヵ月で1億ユーザーを突破した、対話型AIサービス「ChatGPT」。実は真に注目すべきは、そのベースの技術である大規模言語モデル「Transformer」によるパラダイムシフトです。
本記事では、2023年1月19日に開催したセミナー「DX・新規事業担当者のための『1時間でChatGPTの概要と展望を学ぶ集中講義』」で解説した、ChatGPTが注目される背景やTransformerの概要や今後の展望などについてご紹介します。
▼ ChatGPT活用の企業向け生成AIサービス【無料トライアル予約受付中】

株式会社エクサウィザーズ AI新聞編集長
湯川 鶴章

米カリフォルニア州立大学サンフランシスコ校経済学部卒業。サンフランシスコの地元紙記者を経て、時事通信社米国法人に入社。シリコンバレーの黎明期から米国のハイテク産業を中心に取材を続ける。通算20年間の米国生活を終え2000年5月に帰国。時事通信編集委員を経て2010年独立。2017年12月から現職。主な著書に『人工知能、ロボット、人の心。』(2015年)、『次世代マーケティングプラットフォーム』(2007年)、『ネットは新聞を殺すのか』(2003年)などがある。趣味はヨガと瞑想。妻が美人なのが自慢。
結論:注目すべきはChatGPTのベースとなった「Transformer」によるパラダイムシフト

まずは今日のセミナーの結論です。
最近、対話型AIサービスの「ChatGPT」が注目されていますが、実は真に注目すべきはそのベースになっている「Transformer」という大規模言語モデルです。このTransformerが、 新しいAIのパラダイムを開いたということです。
この後詳しくお話ししますが、ChatGPTは、学習済みの巨大な「基盤モデル」をチャット目的に微調整しただけの「特化型モデル」です。今後、言語だけではなくて、ロボットや対人システムなどの分野でも巨大な基盤モデルが複数登場してくることが予想されます。
そして、それを微調整した特化型モデルが、法律やヘルスケア、教育などの様々な領域で無数に登場して、社会に大きな影響を与える。我々はそういうところに立っているのです。
ChatGPTとは?
まずは、改めてChatGPTとは何なのか、注目されている背景と一緒にご説明します。
ChatGPTは、2022年11月にOpenAIがリリースした対話型AIサービスで、2017年にグーグルが発表した「Transformer」という大規模言語モデルをベースにしています。
注目されている背景には、質問に対して人間が回答しているかと思うほどの自然な回答を返せるという点と、それを一般ユーザーが無料で手軽に試せるようになったという点があります。
世の中では、こうしたAIの急速な進化がこれから起こっていくと思われがちですが、実はパラダイムシフトはTransformerが発表された2017年から始まっているのです。
ChatGPTのベースである「Transformer」とは?これまでと比べて何が凄いのかを解説
まずTransformerを紹介する前に、潮流の技術的・歴史的背景を簡単にご説明します。
2012年に、グーグルが猫の写真を自動判別するAIモデルを開発したことから、コンピュータは『目を持った』と言われるようになりました。
これは、「ディープラーニング(深層学習)」と呼ばれる、コンピュータに膨大なデータを学習させ、自動的にパターンやルールを学び、高度なタスクを実行する技術を使ったものです。このディープラーニングが2010年代から始まった第3次AIブームを牽引して、1つのパラダイムを築いてきました。
次のパラダイムを起こしたのが、2017年にグーグルが発表した言語モデル「Transformer」です。
これまでも言語モデルはあったのですが、これまでと性能が段違いなのです。スタンフォード大学の研究者たちも「Transformerは、単なる言語モデルというより、基盤モデルである。AIのパラダイムシフトを牽引している」という風に言っています。

(出典:湯川鶴章の講演資料)
並列処理により、文脈を考慮した文章生成や、文章の意味理解ができる
では、Transformerがどのようなものか。これまで自然言語処理で多く用いられてきたディープラーニングのアーキテクチャ「RNN(Recurrent Neural Network)」と比較してご説明します。瞬間的にデータを捉えるRNNに対して、Transformerは連続的にデータを捉えることができるという特長を持ちます。
もう少し詳しくお伝えすると、RNNは、文章の中の単語のように連続するデータを順番に認識していって、関係性を理解した上で、次に何が来るのかというのを予測するモデルなのです。
例えば、「あけまして」という言葉があった場合、大体はその後に「おめでとうございます」と続くことが多いですよね。ところが、「まいど」という言葉の後には、「(まいど)おおきに」と続くかもしれないですし、「(まいど)あり」や「(まいど)ありがとうございます」といった言葉が続く可能性もありますよね。
こういった場合、これまでの言語モデルは、順番に単語を処理していき、次にどのような言葉が続く可能性が高いかということを予測していました。
(出典:湯川鶴章の講演資料)
これに対して、Transformerは並列処理ができるアーキテクチャです。つまり、文章であれば、単語間の関係性や文脈をより正確に理解することができるということです。
具体的には、これまでは文章の最初の方に「Aさん」という固有名詞が出てきて、最後の方に「彼」という代名詞が出てきた場合、「彼」が誰のことを指してるのか理解できない、ということが起こっていました。これがTransformerによる並列処理によって、位置に関係なく「彼」が誰を指すのか判断できるようになったのです。

(出典:湯川鶴章の講演資料)
大規模かつ複雑なモデルを効率的に構築できる
この並列処理のさらに凄いところは、学習を高速で行えるため、複数のコンピューターを繋げた「クラスター」と呼ぶシステムを作ることで、大規模かつ複雑なモデルを効率的に構築できるところです。
資金力があり、膨大な数のコンピューターを持つことのできるテック大手の開発競争によって、モデルの精度がどんどん良くなっている、というのが今起きていることです。
ラベル付けが不要になった
加えて、Transformerは、要素間のパターンを数学的に発見することができるので、ラベル付けが不要なんです。ラベル付けというのは、AIのモデル構築に必要なデータに対して正解のラベル(タグやカテゴリーなど)を付けることを指します。
Transformerを使うことで、ラベル付きデータの作成コストを削減し、またラベル付きデータが不足している場合でも高品質なモデル構築ができるようになります。
Transformerのこれまでの進化と今後の可能性
Transformerのこれまでの進化
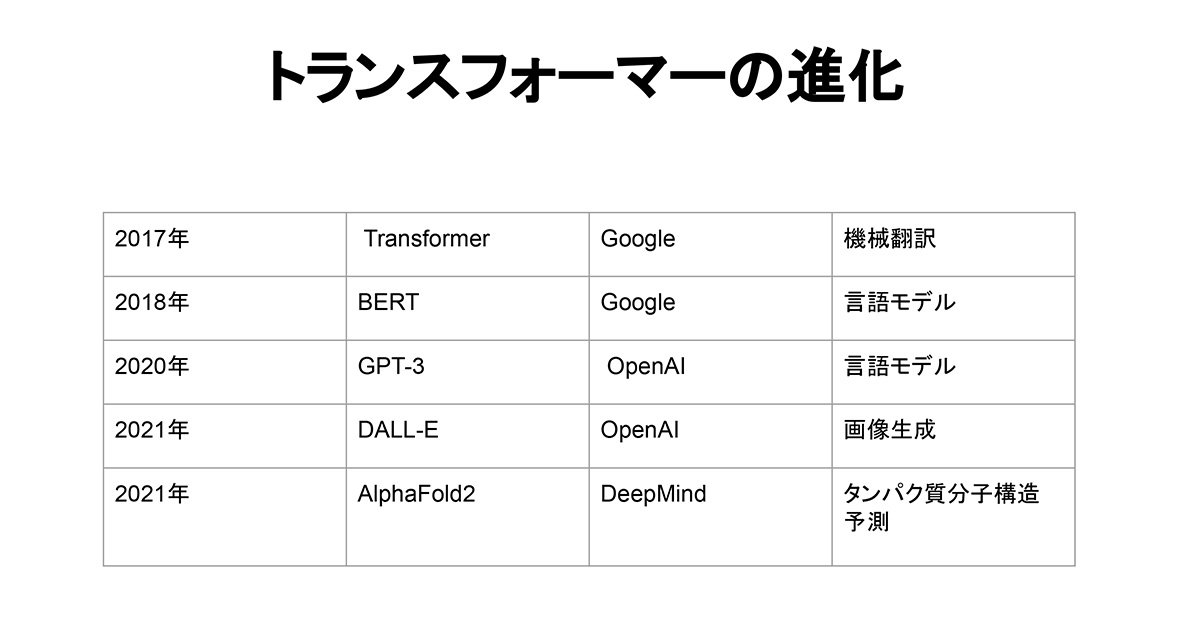
Transformerが、2017年にグーグルから発表されてから、どのような進化をしてきたのかご紹介します。まず、2018年に、2017年当初は機械翻訳モデルとして発表されたTransformerを言語モデルとして拡張した「BERT」がグーグルから発表されました。
続いて2020年に、Transformerをベースにした「GPT-3」という基盤モデルをOpenAIが発表しました。今注目されているChatGPTは、このGPT-3の後継を使った、“チャット”目的に特化したAIモデルです。
2021年には、OpenAIは「DALL-E」という画像生成モデルも発表しました。
同年、グーグル傘下のDeepMindというイギリスの会社が、「AlphaFold2」というタンパク質分子構造予測のモデルを発表しました。このAlphaFold2っていうのは、生物学50年の歴史の中で1番のブレイクスルーだという話を聞きます。これによって、生物学や医療がものすごく前進したというのです。
(出典:湯川鶴章の講演資料)
Transformerの可能性
続いて、Transformerの可能性ついて見ていきましょう。
今後、自然言語処理以外でも、テキスト生成や要約、画像生成、チャットボット、プログラミング翻訳などの領域で、基盤モデルが次々に登場することが予測されます。

(出典:湯川鶴章の講演資料)
基盤モデルと特化型モデルとは?可能性と課題とともに解説
基盤モデルと特化型モデルとは
ここで、「基盤モデル」と「特化型モデル」について、改めて整理してご説明します。
基盤モデル(Foundation Model)とは、大量のデータで学習したモデルで、微調整するだけで比較的簡単に、ある特定の目的に特化した「特化型モデル」を作ることができるモデルです。
ChatGPTを例に挙げると、GPT-3が事前学習済みの「基盤モデル」で、ChatGPTがチャットという目的に特化した「特化型モデル」というわけです。
今後も言語やビジョン(画像処理や視覚技術)、ロボット、対人システムなどの領域で、基盤モデルが次々と登場し、法律やヘルスケア、教育などの分野で目的特化型モデルを生み出していくと考えられています。
基盤モデルと特化型モデルの可能性と課題
基盤モデルとしては、今後どんなものが出てくるかというと、ビジョンやロボット、接客対人システムが多く出てくると予測しています。
言語については、今の時点でもかなり精度が上がっています。今後、より精度を上げていくためには、我々人間が言語を習得する際のように、テキスト情報だけでなく、画像や音声情報などマルチな情報を学習できるようにしていく必要があるだろうと思います。
ビジョンについては、これまではタグ付けされたデータセットで学習する必要がありました。ですが、Transformerはタグ付けしなくても学習できるというのが1つの強みなので、これからはWeb上の動画や写真が全て学習データになり得ます。この領域もこれからすごく進化するだろうなと思います。
ロボットについても大きな進化が予測されますが、言語やビジョンと違って、Web上にデータが溢れていないので、人間の動きを撮影した動画などを学習モデルにできないか、というのを今模索中だそうです。
接客対人システムについては、ロボティクスと組み合わせた接客ロボットが実用化されていくと考えられています。
応用領域の可能性と課題
前述の基盤モデルを微調整した特化型モデルもこれから無数に出てくると思われます。
まず、ヘルスケアの領域では、DeepMindが開発したタンパク質分子構造予測モデルが、非常に大きなブレイクスルーだと言われてるように、同じようなモデルがタンパク質以外でも出てくるはずです。また、病院で患者と接する対人システムも出てくるだろうと思います。
法律の領域では、裁判資料なども膨大なテキストデータが存在するので、これも基盤モデルが作られ始めています。実際に、弁護士AIが米最高裁で弁論することが決まっているようです。ただ、AIに公正な判断ができるのかどうか、公正とはどういう意味なのかということなどはこれからも議論が必要だと思います。
教育の領域は、生徒1人1人の理解度を把握して、進捗度合いに沿って生徒の学習を導くAIモデルというのが求められているのですが、今のところまだ実現してないです。ただ、巨大な言語モデルと対人モデルが発達してきているので、これから良いものが出てくる可能性は高いと思います。