
米イェール大学助教授・成田悠輔氏が語る「Web3時代のAIとDX」~AIを活用した民主主義や社会政策設計のアップデート~
企業のビジネスから社会のデザインに飛躍するためには何が必要なのか。2022年10月19日に開催された「ExaWizards Forum 2022」の基調講演において、米イェール大学助教授 成田悠輔氏が語った、大胆なWeb3時代のAI活用法とは──。
米イェール大学助教授(経済学)
半熟仮想株式会社 代表取締役 成田悠輔氏
夜は米国でイェール大学助教授、昼は日本で半熟仮想株式会社代表。専門は、データ、アルゴリズム、数学、ポエムを使ったビジネスと公共政策(特に教育)の想像とデザイン。研究者として「社会的意思決定アルゴリズムをデータ駆動にデザインする手法」を開発し、機械学習ビジネスから教育政策まで幅広い社会課題に実装、多分野の学術誌・学会に査読付学術論文を出版する。事業者として、サイバーエージェント、ZOZO、ニューヨーク市、戸田市などと共同研究・事業を行う。東京大学経済学部卒業(最優等卒業論文に与えられる大内兵衛賞受賞)、米マサチューセッツ工科大学(MIT)にてPh.D.取得。一橋大学客員准教授、スタンフォード大学客員助教授、東京大学招聘研究員、独立行政法人経済産業研究所客員研究員などを務める。
AI活用は企業のビジネス領域から公共領域へと拡大
社会貢献とビジネスを両立させる「AI」とは何でしょう。典型的なイメージでいうと、AIのビジネス活用だと思います。特にWebビジネスでの応用ですね。「ZOZOTOWN」や「Yahoo!ショッピング」「メルカリ」といったECサイトを訪問すると、ずらりと商品が並んでいます。ここにどんな商品を陳列し、サイトを訪れたユーザーに何の商品を推薦すればよいかはとても重要な問題です。
物理世界の路面店であれば、どこに何を並べて、いくらの値札を貼るかを決めるのは当然人間です。しかし、Webサイトではソフトウェアが行っています。最近ではAIを活用することも増えてきました。
例えば、私が関わったZOZOTOWNさんのプロジェクトでは、トップページの一部を使って商品の推薦を決めるAIの改善する実験を行いました。もともと使っていた古いアルゴリズムとパフォーマンスを新しいアルゴリズムに移行した結果、クリック率換算で30〜40%ほど改善することができました。
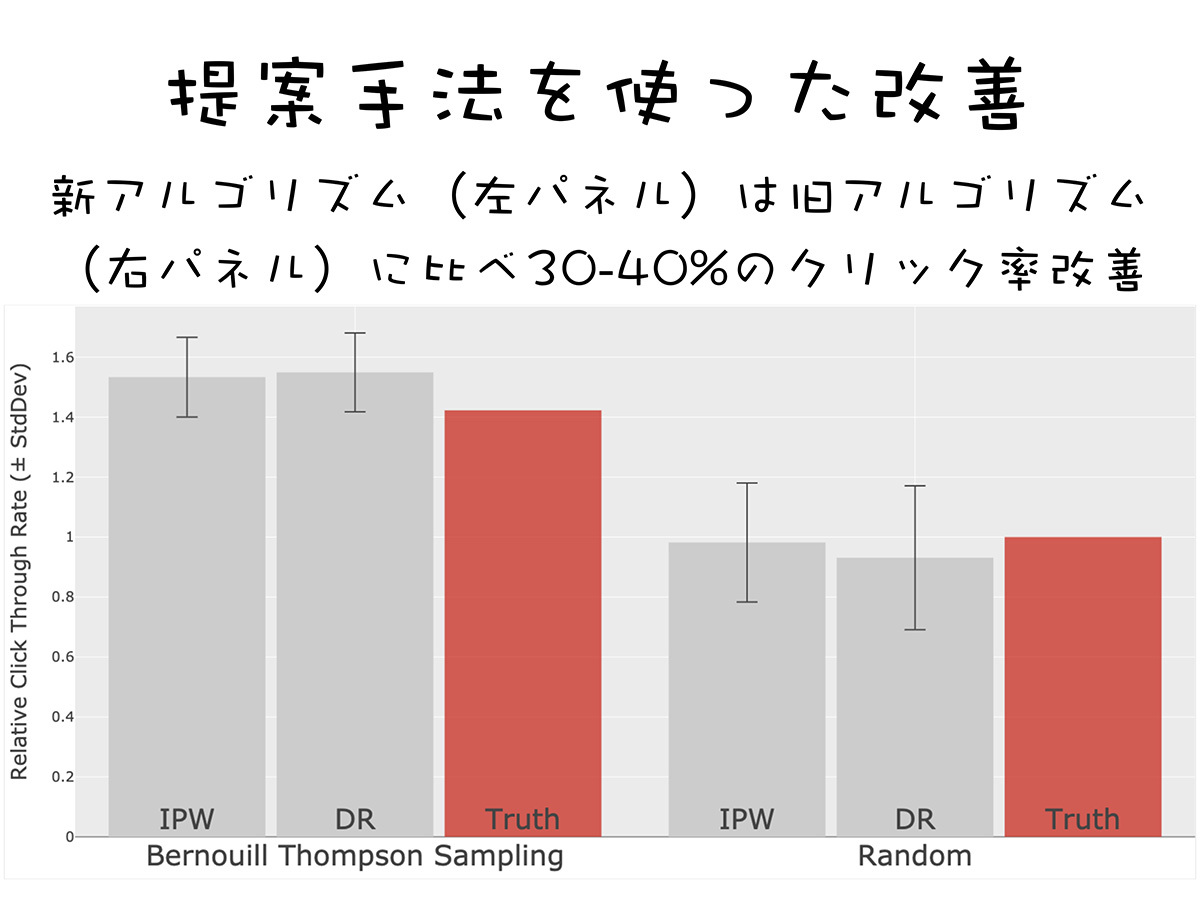
(出典:成田悠輔氏の講演資料)
さらにZOZOTOWNさんとの共同事業では、サービスの一部を使った実験や実装、ファッション推薦に関するデータやソフトウェアを世界に公開しました。
例えば、ユーザーがどんな商品を見て、どのアイテムをクリックしたかという数千万件規模のデータを蓄積。そのデータを使って推薦AIを開発するための開発基盤を作り、日本語と英語のドキュメンテーションを公開するといった試みです。
そのほかにも、日本企業の国産ビジネスや事業を起点にしたAI、アルゴリズム、データ関連のR&Dを世界中に公開・発信するプロジェクトをいくつかやっています。

(出典:成田悠輔氏の講演資料)
こうしたAIの実活用は、Webビジネスやゲーム産業、テスラのようなハイテク製造業など、いくつかの産業に限定されているのが現状です。しかし今後数十年にかけて、AI活用領域はより幅広く、様々な領域にしみ出していくと予想されます。
その中でも、特に重要な領域が公共領域だと思います。教育や医療はもちろんのこと、労働領域や司法・警察領域、さらには軍事領域もどんどんAI化していくでしょう。
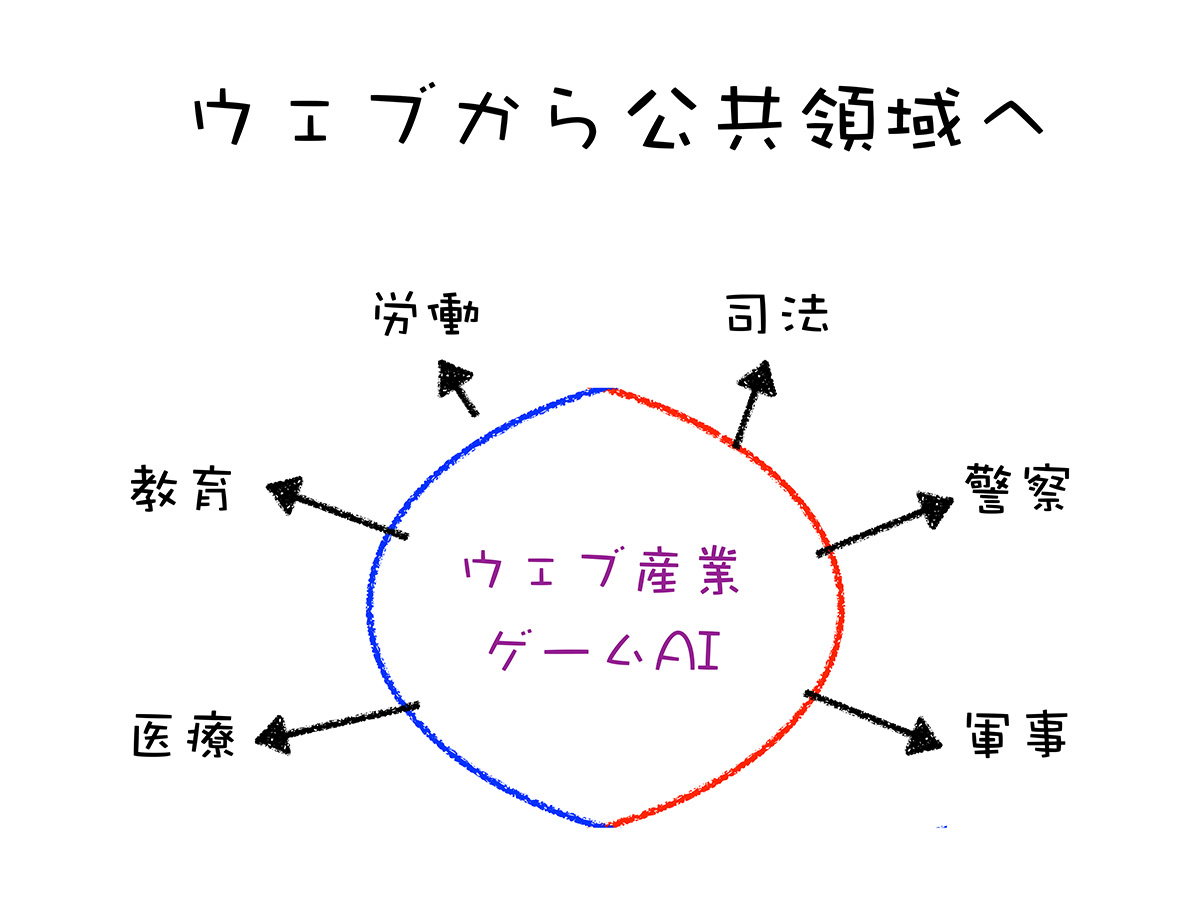
(出典:成田悠輔氏の講演資料)
AIを公共領域において活用する:ミクロなレベル編
AIを公共領域において活用するためには、いくつかのレイヤーに分けて考える必要があります。一つはミクロなレベルでの活用です。このミクロなレベルでの活用は、いわば個人の問題を解決するためのAI活用ということになります。
典型的な例としては、健康や医療問題でのAI活用です。例えば、スマートウォッチやスマートイヤホン、スマートグラスなど。近年、私たちは自分たちの体の表面をデジタルデバイスに明け渡すようになってきました。今後はおそらくそれらがチップ化されて体の中に埋め込まれたり、コンタクトレンズや洋服に内蔵されたりといったことが加速していくと思います。
そして、体表面につけたセンサーから心拍数に関するデータが取れるようになり、ゆくゆくは血圧計などもスマートウォッチと一体化していくでしょう。そうなると、例えば心臓発作の予防や予測は、スマートウォッチ経由でほぼ完了する可能性もあります。
健康や医療の問題がAI化されていくことで、重篤な疾患を予防や予測するような重大なレベルから、ダイエットやヨガ・瞑想などのライトなレベルまで、人間を健康な方向に行動誘導していく。これが現在進行形で個人の生活レベルで起きているミクロな例になります。

(出典:成田悠輔氏の講演資料)
AIを公共領域において活用する:マクロなレベル編
ミクロなレベルでのAI活用のほか、公共領域や政策領域でのAI活用の場合には、よりマクロなレベルでの活用になっていくと思います。まだ現実世界では実装されていない潜在的な活用、例えばコロナ禍における補助金施策などの社会政策の設計です。
コロナ禍において病院の経営状態が悪化し、日本でもアメリカでも巨額の補助金が注ぎ込まれたことは、皆さんもご存じだと思います。日本では厚労省を起点に数兆円の補助金が流し込まれたようですし、アメリカでは日本円換算で数十兆円を超えるコロナ病床補助金が各地の病院に注ぎ込まれました。
公式の目的としては、コロナ患者を受け入れるための病床を増やすためであったり、あるいは人を雇ったり、いい設備を導入したりなど。それまで以上にコロナ患者の方を受け入れられるのではないかという期待があったわけです。
では、実際の効果はどうだったのか。アメリカで実際のデータを使って測ってみました。その結果、コロナ病床補助金がコロナ患者の受け入れ数などに与える影響は、全くゼロだったということがわかりました。
つまり補助金は、つぶれそうな病院の経営状態を改善したという効果はあったのかもしれません。ただ、コロナ患者皆さんを受け入れたり、診療をしたりするという医療行為そのものには何の効果もなかったのです。
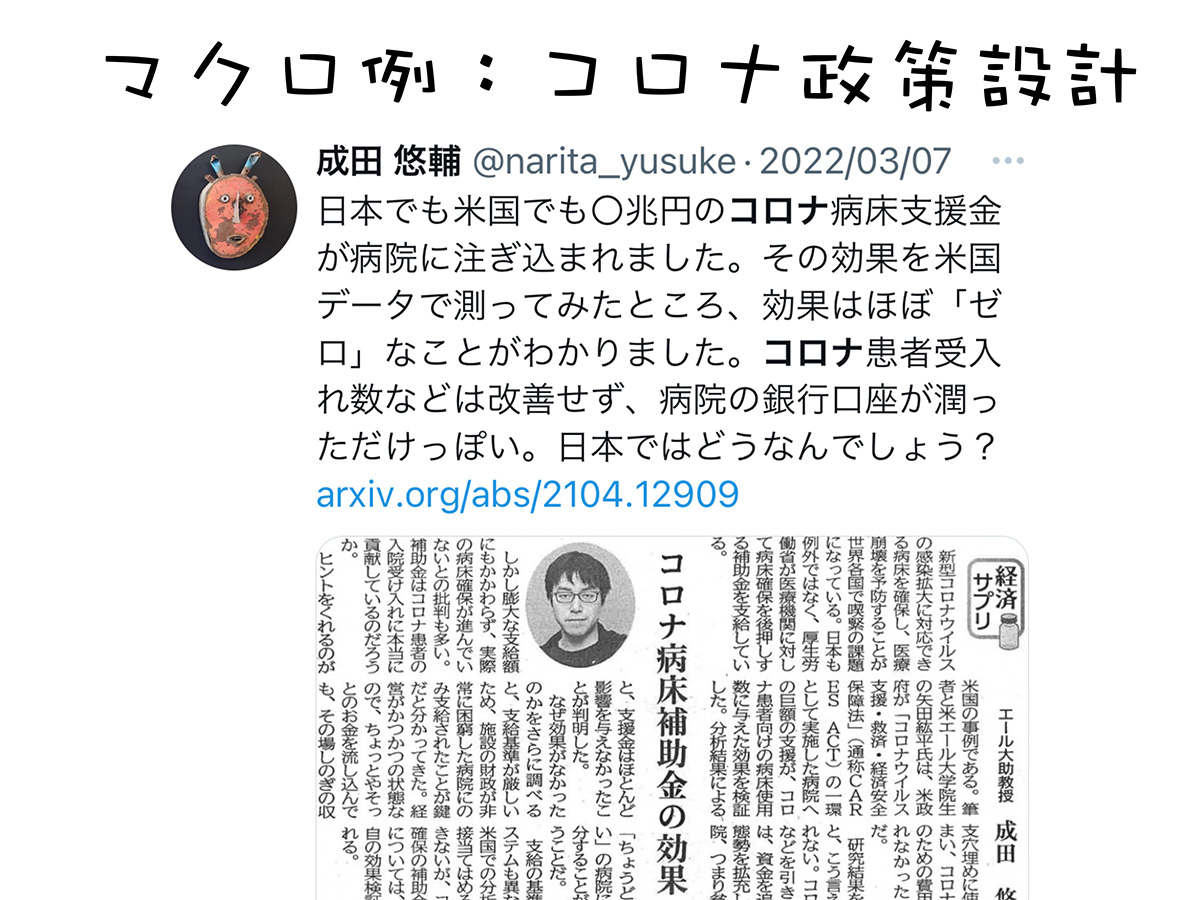
(出典:成田悠輔氏の講演資料)
では素朴な疑問として、日本ではどうだったのか気になりますよね。これはコロナ禍における補助金施策の設計をAI的な問題、機械学習的な問題として解釈することができるのではないかと捉えています。
機械学習やAIは、今我々がどんな状態にあるのか、どういう状況に直面しているのかという情報を与えたときに、そこで何をするのが正解かを決めるルールを作り出す一連の技術。コロナ禍における補助金政策の問題も、ある種の機械学習の問題として形式化することができるはずです。
つまり、いま我々がどんな状況にいるかを表す入力変数のXが与えられたら、それに応じて正解のYを抽出する。例えばXが画像で、Yがその画像の中にネコが入っているかどうかの正解。こういった正解を決めるルールやアルゴリズムをデータから学習するのが、機械学習やAIの営みです。
入力変数は様々な病院の属性、規模、経営状態、コロナ対応履歴など。機械学習的な定義で先の経営状態の悪化、これまでのこのタイプなどの入力情報を与えることで、各病院の正しい補助金の支給額を決めるルールを作ることができます。
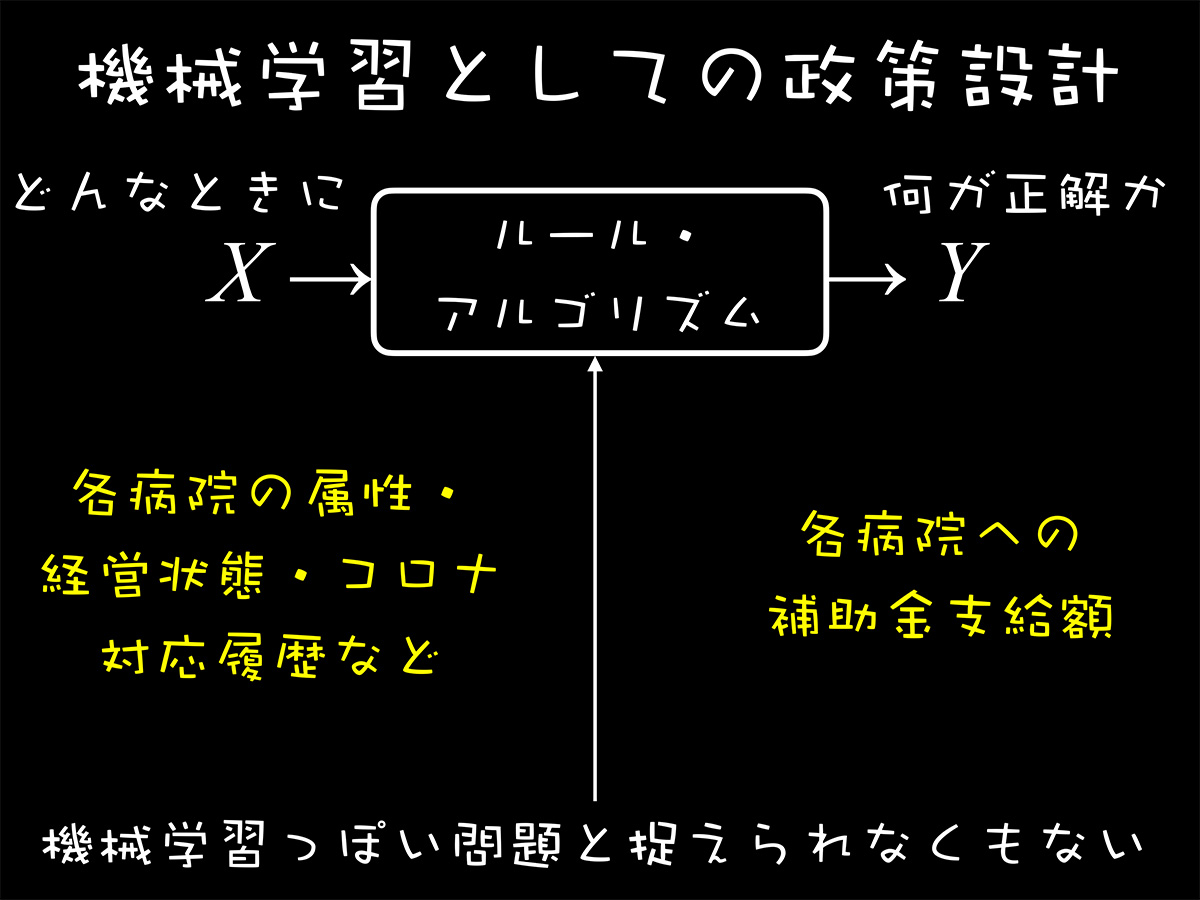
(出典:成田悠輔氏の講演資料)
アメリカでは、病院の属性に基づいて補助金の金額が簡単な公式で決まる単純なルールに従って作られていました。日本もより最適でより社会的に望ましいルールやアルゴリズムを作るために、機械学習やAI的な発想を政策ルールのデザインに適用できると思います。
ただ、こうしたマクロな公共問題課題にAIが活用されていないことには理由があります。
そこにいくつかの壁が立ちはだかったからです。例えば一つ目の課題は、マクロな政策のデザイン、あるいはマクロな政策的・公共的な意思決定を行うルールやアルゴリズムやデザインを考える場合、その単位というのは国とか自治体になってしまうこと。
実質的なデータ数や標本数は、国や自治体の数くらいしか手に入らず、データ数がすごく少ないAI環境になってしまう。そうすると小さなスモールデータから適切なルールを学習する方法というのを導かなければならない。これは大量のデータから課題解決することが望ましいとされているAI活用とはずいぶん趣が異なると言えます。
さらには、予測結果のお手本役となる正解データや訓練データを作ることが非常に難しく、ABテストや実験もできないという問題もあります。本来であれば、どのようなコロナ補助金施策を行ったらどんな結果が起きるのか、様々なルールを異なる国や自治体に割り当てた結果を見るABテストを行うのが理想です。
しかし現実的に観測できるのは、その国がたまたま政治・行政的なプロセスを経て使うことになったルールが、たまたま作り出した結果のデータのみ。こうした実験や、何が正解なのかを教えてくれるデータを作り出すことが難しい環境で学習しなければならないという難しい問題があるのです。
さらに根本的、概念的な難しさもあります。それは学習を行う際に、何ができたらより良い学習ができたと言えるのかという損失関数や目的関数、価値関数などが様々な政策を協議する上で不明確であることが多いという問題です。
典型的なAI課題であれば、それがうまくいったか、失敗したかを決める損失関数や目的関数があきらかにあるわけです。それとは違って、損失関数や目的関数が何なのかという目的自体を、私たち自身が内側から見つける必要がある。こうした問題はより大きな社会制度や社会インフラのデザインで考えると、さらに明瞭になります。

(出典:成田悠輔氏の講演資料)
AIで取得した無意識の民意データを活かす無意識データ民主主義
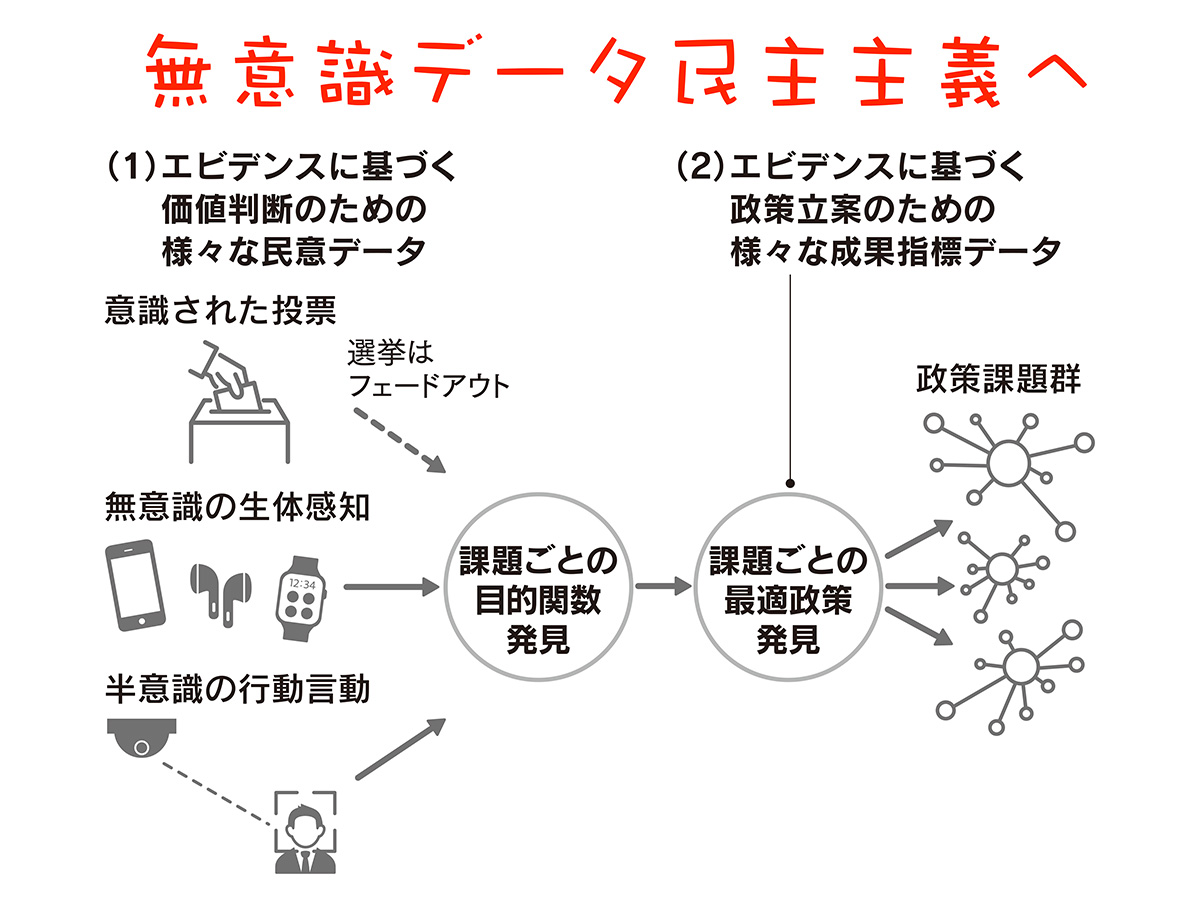
私が最も興味を抱いているのは、民主主義や資本主義と呼ばれる政治経済の根本的なインフラを、今世紀風のデジタル技術を使ってアップデートできないかということです。紙と鉛筆を使った選挙を通じて実行される民主主義のプロセスを何らかのかたちで、データ化、知能化ができないかという問題です。
民主主義における問題については、先ほどのコロナ禍における補助金施策デザインのように、データの変換とそれに基づく意思決定の過程だと捉えています。
民主主義とは人々が何を求めているか、どんな政策や国家を求めているかといった民意を表す何らかの情報に意思決定ルールやアルゴリズムを与えて、社会的決定を行うこと。現代において、その一番わかりやすい民主主義的な仕組みが、選挙なのだと思います。
選挙の日に有権者が投票所に行き、投票用紙に政治家や政党の名前を書く。この投票用紙に書かれた情報が人々の民意を表すデータであると仮定し、多数決の固定された選挙ルールを決める。そしてどの候補者を選び、どの政党が政権を握るかという意思決定が行われる。人間が手作りで作り出したデータと、それに基づく非常に粗い意思決定です。
しかし、現在の情報環境、技術環境、データ環境を考えれば、これよりもはるかに豊かでリッチな民主主義があり得る気がします。ある意味で無意識データ民主主義と呼べる、民主主義の考え方です。
もちろん選挙で投票用紙に書かれた情報は、人々の民意を表す一つの情報源であるとは思います。ただ同時に現代の情報社会では、それ以外にも人々の民意や世論をくみ取ることを可能にする大量のチャネルが存在しています。
例えば、SNSで人々が政治や政策について文句を言う。これはすごくわかりやすい例だと思います。それ以外にも、街中で政治家の該当演説を聞いてどんな反応を示したかという情報は、監視カメラがとらえているかもしれない。さらにはテレビに映ったニュースを眺めていた人が、どんな反応を示していたかという生体反応も、先ほどのスマートウォッチやスマートデバイスを通じて取得できるようになるでしょう。
意識された投票という行動を超えた、無意識レベルの生体行動、半分認識されていたり意識されていなかったりする様々な行動や言動と、世論の意思を示す無数のデータを元に民意として収集・蓄積できると考えます。

(出典:成田悠輔氏の講演資料)
その様々な大量のデータを組み合わせることによって、それぞれの政策課題に対して人々がどんな意見を持っているのか、あるいは価値観を持っているのか。さらに突き詰めれば目的関数や損失関数とデータに基づいて学習するAIや機械学習が使えるのではないか。
その目的関数や損失関数が一旦発見されてしまえば、その関数を最適化する意思決定を発見するのは、今Webビジネス領域で行われている典型的で確立されたAI活用の延長線上にあるのではないかと捉えています。
民主主義の入力も、そして出力がこれまでとは比較にならないくらい高次元化してチャネル化する。こうした現代的な民主主義のあり方、あるいは民主主義のAI化といったものがあり得るのではないでしょうか。
(出典:成田悠輔氏の講演資料)
ただし、この課題ごとの目的関数の発見をデータに基づき、どう自動化するかという問題が壁として立ちはだかります。それらに対しては、企業のビジネスでAI技術の拡張で手段の改善を行ってきた経験が重要になってくると思います。
つまり事業KPIが与えられたときに、そのKPIを最適化する手段をどうやったら発見できるかという課題を解決するAI技術などです。これから社会貢献や公共の領域に触手を伸ばしていくためには、AIが手段改善を超えて目的革命も同時にできる方向に技術が拡張していかなければなりません。
これまで企業のビジネス問題の中で蓄積されてきた「社畜の技術と公僕の意識」を組み合わせることによって、AIの応用領域をこれまでの「会社から社会へ」と拡張しながら進む必要があるのではないか。そのように民主主義や政策の問題をAIの観点から考えています。