
【2026年最新】生成AIの著作権侵害リスクとは?企業が策定すべきガイドラインと対策

「業務効率化のために生成AIを活用したいけれど、著作権侵害で訴えられるのが怖い」
「現場からAI利用の申請が来ているが、どのようなルールで許可を出せばいいのか分からない」
社内で生成AI活用を推進する立場では、同様の悩みを抱えるケースが少なくありません。経営層からはスピード感を求められ、一方で法務部からは厳格なリスク管理を求められる。その板挟みになり、具体的なアクションが取れずにいるケースも少なくありません。
結論からお伝えすると、生成AIの著作権リスクは、正しい法的理解と適切な社内ルールの運用によってコントロールできる可能性が高まります。むやみに恐れて「全面禁止」にするのではなく、リスクを正しく評価し、管理下に置くことが生成AI活用推進の鍵となります。
この記事では、生成AIにおける著作権侵害のリスクについて、文化庁の見解や最新事例を交えて解説します。さらに、明日から使える「生成AIガイドライン策定のポイント」も紹介しますので、ぜひ参考にしてください。

※デロイト トーマツ ミック経済研究所「LLM(大規模言語モデル)を自律的に連携させ非定型業務を自動化するAIエージェント ソリューションサービスの市場動向 2025年度版
※富士キメラ総研「2026 生成AI/AIエージェントで飛躍するAI市場総調査」<2024年度実績・サードパーティ対話型生成AIアプリケーション・ベンダーシェア>
生成AIと著作権の基本|「学習」と「生成」で変わるルール
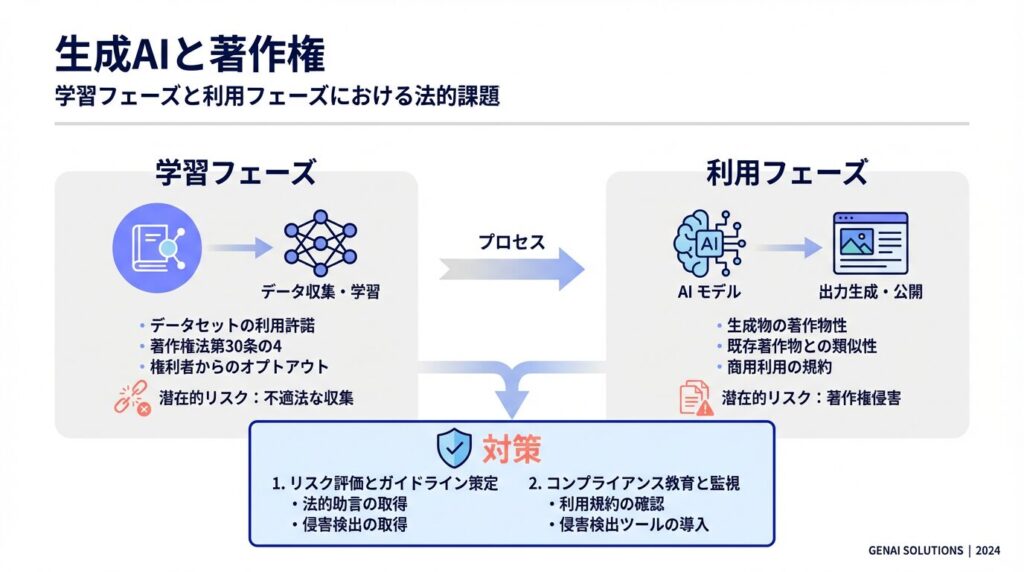
生成AIの著作権について考える際、最も重要なのは「どの段階の話をしているか」を区別することです。大きく分けて、「AIを作るとき(開発・学習段階)」と「AIを使うとき(生成・利用段階)」の2つのフェーズがあります。
この2つを混同してしまうと、「AIは著作権フリーだから大丈夫」といった誤解や、逆に「AIはすべて危険」といった過剰反応が生まれてしまいます。
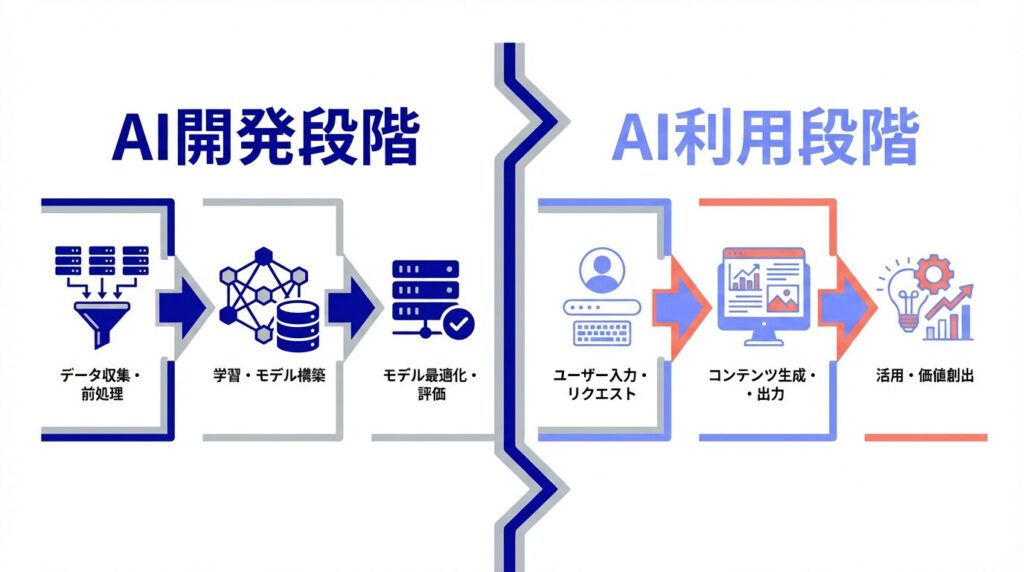
【開発・学習段階】原則として許可不要(著作権法第30条の4)
まず、AIモデル自体を開発したり、AIにデータを学習させたりする段階についてです。
日本の著作権法では、第30条の4という規定により、AIに学習させる行為は「情報解析行為」として非享受利用に該当するため、著作権者の許諾なく著作物を利用(学習)できることになっています。
| 第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合 |
|---|
出典:衆議院「著作権法」
これは、AIによる情報解析行為は、作品を鑑賞する、音楽を聴くなどの著作物の創作性を楽しむこと(享受)が目的ではなく、あくまでデータとして処理することが目的だからです。この柔軟な権利制限規定のおかげで、日本は「機械学習パラダイム」にとって有利な環境と言われています。
ただし、何でもありというわけではありません。
特定のクリエイターの画風を模倣するAIを作るために、その人の作品だけを意図的に学習させる場合(過学習)は享受目的があるとして、第30条の4は適用されません。
また、「著作権者の利益を不当に害する場合」は例外として著作権者の許可が必要になります。
例えば、AI 学習のための学習データとして販売されている画像データベースなどを、購入せずにコピーして学習させる場合が該当します。
出典:文化庁「AI と著作権に関する考え方について」2024年
【生成・利用段階】通常の著作権侵害と同じ扱い
次に、企業のDX担当者が最も注意すべき「生成・利用段階」です。これは、ChatGPTやMidjourneyなどの生成AIを使って文章や画像を作成し、それを社外に公開したり商用利用したりするフェーズを指します。
この段階では、「AIが作ったものだから著作権侵害にはならない」という特例はありません。 人間が手で描いた絵や文章と同じように、既存の著作物に似ていれば侵害になるリスクがあります。
つまり、利用者が意図していなくても、AIが出力したものが既存のキャラクターや作品に酷似していた場合、それを利用(公開・販売など)した企業や個人が法的責任を問われる可能性があるのです。
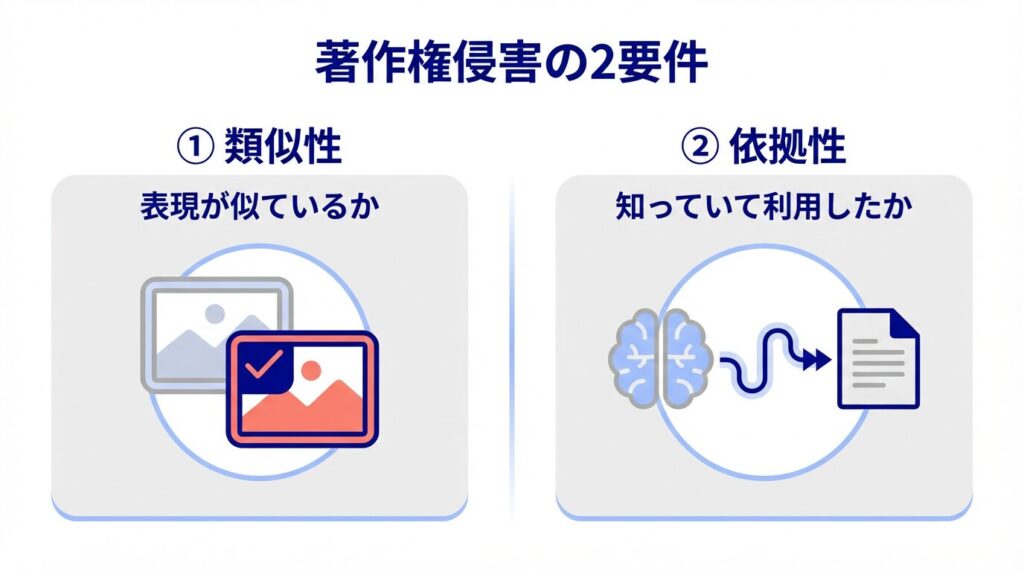
どこからが著作権侵害?判断基準となる「2つの要件」
では、具体的にどのような場合に「著作権侵害」となるのでしょうか。
これまでの判例や文化庁の見解では、主に「類似性」と「依拠性」という2つの要件を満たしたときに侵害が成立すると考えられています。
① 類似性:既存の作品と「表現」が似ているか
1つ目は「類似性」です。これは文字通り、生成されたものが既存の著作物と似ているかどうかです。
ここで重要なのは、単なる「アイデア」や「作風」が似ているだけでは著作権侵害にはならないという点です。著作権法は具体的な「表現」を保護するものだからです。
- セーフの可能性が高い例: 「〇〇先生のようなタッチの水彩画」といった画風の類似、「勇者が魔王を倒す」といったありふれたストーリー展開。
- アウトの可能性が高い例: 特定のキャラクターの容貌がそのまま再現されている、小説の文章表現が酷似している。
② 依拠性:既存の作品を「知っていて」利用したか
2つ目は「依拠性」です。これは、既存の著作物に依拠して(=それを元にして)作成されたかどうかを指します。
まず、AI 利用者が既存の著作物を認識していたと認められる場合は、依拠性が認められる可能性があります。
文化庁の見解としては、「AI利用者が既存の著作物を認識しているか」や「AI利用者が既存の著作物を入力したか」が考慮要素となるようです。
しかしながら、生成AI特有の問題として、「AI利用者がその作品を知らなかったとしても、AIが学習データとしてその作品を取り込んでいた場合、依拠性は認められるのか?」という議論があります。
文化庁の見解としては、AI 利用者が既存の著作物を認識していなかったが、AI 学習用データにその著作物が含まれる場合も通常依拠性が認められるとしています。
したがって、リスク管理の観点からは、「ある有名な作品などの既存の著作物に似てしまった場合は、利用を控える」のが安全でしょう。
出典:文化庁「AI と著作権に関する考え方について」2024年
日本国内での生成AI著作権問題:重要事例8選
日本国内で発生した生成AI関連の著作権問題について、業界団体による声明・法的措置・SNS炎上事例を含む代表的な8つの事例を紹介します。これらは権利者団体・政府・警察による対応が伴い、クリエイターや業界全体で大きな議論を呼んだものです。
OpenAI「Sora 2」による日本のアニメ・漫画キャラクター無断生成問題(CODA要望書提出)
事例:スタジオジブリや任天堂など100社以上が加盟するCODAが2025年10月28日にOpenAIへ要望書を提出し、日本動画協会と出版社19団体も共同声明を発表し、Sora 2による日本コンテンツの無断学習に抗議しました。
要因:OpenAIの「オプトアウト方式」が権利者の事前許諾を不要とし、クリエイターが求める「オプトイン方式」と対立したことで、業界横断での権利保護の必要性が認識されたためです。
出典:Yahoo!ニュース「Sora 2著作権問題。ジブリ・任天堂ら加盟のCODAが要望書、日本動画協会・出版社も共同声明発表」2025年11月
コンテンツ産業団体による生成AI時代の創作と権利に関する共同声明
事例:コンテンツ産業関連団体が2025年10月31日、OpenAIの映像生成AI「Sora 2」のオプトアウト方式を著作権法原則に反するとして批判し、オプトイン原則の徹底と学習データの透明性担保を求める共同声明を発表しました
要因:権利者の明示的許諾なく著作物を学習・生成する仕組みが「許諾を得てから利用する」という著作権法原則に反し、創作の持続可能性と権利者保護が脅かされると認識されたためです
出典:ITmedia「講談社やKADOKAWAなど19団体が生成AI巡り共同声明 「Sora 2」問題受け」2025年10月
千葉県警によるAI生成画像無断複製の著作権侵害書類送検(全国初)
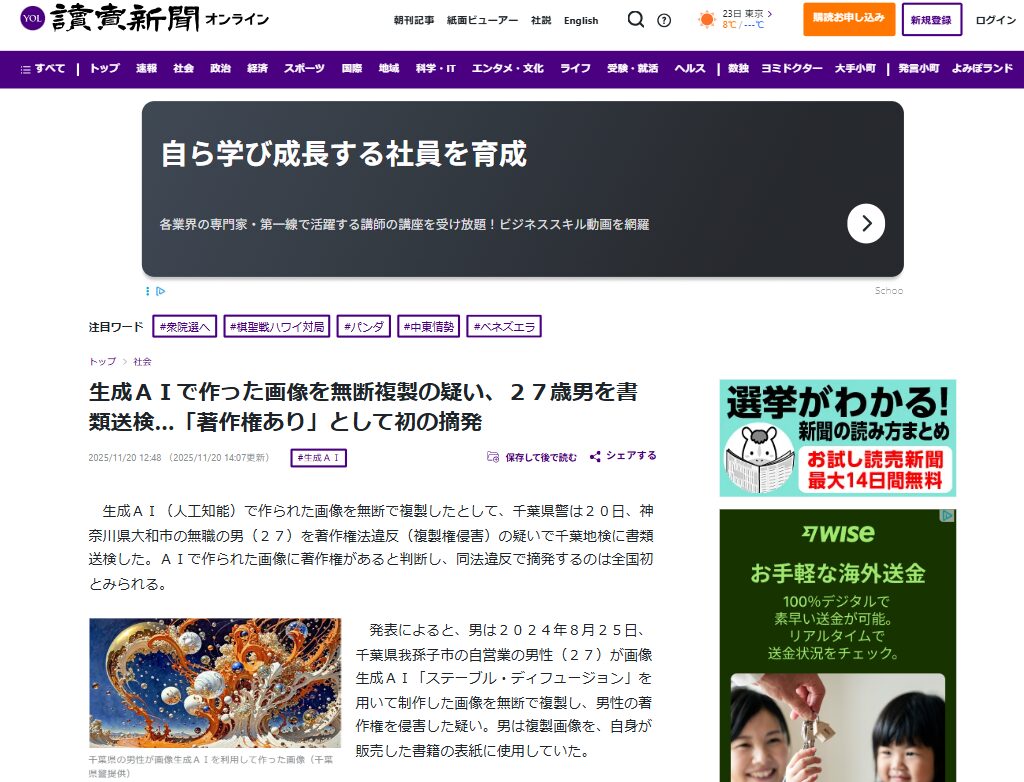
事例:千葉県警が2025年11月20日、生成AI画像を無断複製し書籍表紙に使用した男性を著作権法違反で書類送検し、AI生成画像に著作権を認めた全国初の摘発となりました。
要因:AI生成画像であっても制作者の創作性が認められる場合は著作物として保護されるという司法判断が示され、無断利用が違法行為として取り締まられることが明確化されたためです。
出典:読売新聞「生成AIで作った画像を無断複製の疑い、27歳男を書類送検…「著作権あり」として初の摘発」2025年11月
読売新聞グループによるPerplexity AIへの著作権侵害訴訟

事例:読売新聞グループが記事の無断利用を理由に「Perplexity AI」へ約22億円の賠償を求めて提訴し、国内メディア初の大規模訴訟としてSNS上で報道の未来やフェアユースを巡る議論が炎上しました。
要因:AIによる記事の無断学習および詳細な出力がフェアユース適用外の著作権侵害と捉えられ、報道コンテンツの価値が損なわれることへの強い危機感が法的措置へとつながったためです。
出典: 読売新聞「読売新聞社、「記事無断利用」生成AI企業を提訴…日本の大手報道機関で初」2025年8月
日本雑誌協会による生成AI技術の適切な開発・利用に関する要望
事例: 日本雑誌協会ら出版関連5団体が2023年8月、生成AIによる雑誌・書籍コンテンツの無断学習利用に対して著作権者の権利保護と適正なルール整備を求める共同要望書を提出しました。
要因: 生成AIが著作物を無許諾で学習し類似作品を大量生成することで出版業界の創作活動とビジネスモデルが脅かされ、著作権法の厳格な解釈と権利者保護のための法的規制が必要と認識されたためです。
出典: 一般社団法人日本雑誌協会他3団体「生成AIに関する共同声明」2023年8月17日
日本新聞協会による生成AIの報道コンテンツ利用に関する声明
事例:日本新聞協会が2024年7月17日、生成AIサービスによる報道コンテンツの無断利用について声明を発表し、「ゼロクリックサーチ」による収益減少や誤情報生成のリスクを指摘し、著作権法の抜本的見直しと独占禁止法に基づく対応を求めました。
要因:生成AIが報道機関の知的財産を無許諾で学習・利用し、ユーザーが元サイトにアクセスしない現象が拡大することで取材活動への悪影響が生じており、現行著作権法では十分に取り締まれない状況に加え、誤情報流通による報道の信頼性低下や公正競争上の懸念が法制度整備の必要性を高めたためです。
出典:Ledge.ai「日本新聞協会、生成AIによる報道コンテンツの無断利用について声明を発表」2024年7月
画像生成AIの著作権侵害問題に対する法規制要望
事例: イラストレーターらで構成される「クリエイターとAIの未来を考える会」(約30人参加)が記者会見を開き、画像生成AIによる著作権侵害を訴え、学習前の著作権者許可取得の義務化や対価還元の仕組み構築を政府に求めました。
要因: AI学習における著作物の無許諾利用が可能な現行法規定がクリエイターの搾取につながり、似た絵柄の大量複製や児童ポルノ生成などの悪用被害が発生していることから、著作権者保護のための法整備が急務と認識されたためです。
出典:産経新聞「画像AIは「著作権侵害」 イラスト画家ら法規制訴え」2023年4月
マクドナルド日本法人によるAI広告展開の賛否
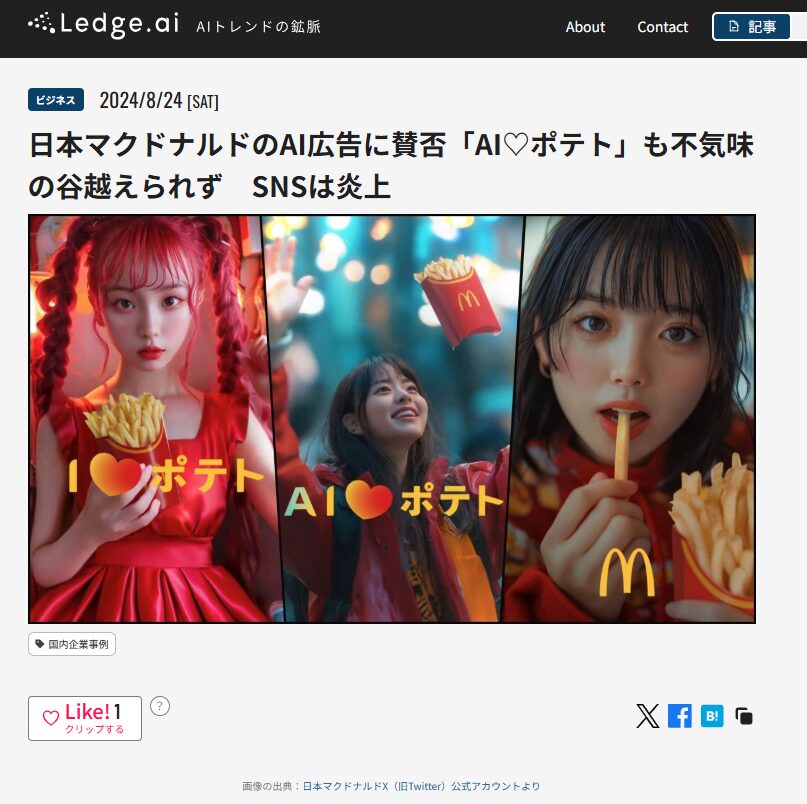
事例:日本マクドナルドが2024年8月、AIクリエイター「架空飴」とコラボしたAI生成広告「AI♡ポテト」を公式X(旧Twitter)で公開したところ、「不気味」「気持ち悪い」といったネガティブな反応が相次ぎ、SNS上で炎上しました。
要因:AI生成された美少女キャラクターが「不気味の谷現象」を引き起こし、過剰に整った顔立ちが逆に不自然で現実味に欠ける印象を与えた一方、効率的なコスト削減やターゲットを絞った広告制作を可能にする点では肯定的評価もあり、AI広告の品質と受容性が社会的評価の分岐点となったためです。
出典:Ledge.ai「日本マクドナルドのAI広告に賛否「AI♡ポテト」も不気味の谷越えられず SNSは炎上」2024年8月
自社で作ったAI生成物に「著作権」は発生するのか?
ここまでは「他人の権利を侵害しないか」という話でしたが、逆に「自社で作ったAI生成物を守れるか(権利は発生するか)」についても触れておきましょう。
原則:AIが自律的に生成したものに著作権なし
現在の日本の著作権法では、著作物は「思想又は感情を創作的に表現したもの」と定義されており、作成者は「人」であることが前提です。
そのため、簡単なプロンプト(「猫の絵を描いて」など)を入力しただけでAIが自動生成した画像や文章には、原則として著作権が発生しません。
つまり、そのままの状態では誰かに勝手にコピーされても、著作権侵害として訴えることができない「フリー素材」のような状態になる可能性があります。
例外:人間の「創作的寄与」があれば発生する可能性
ただし、AIを単なる「道具」として使い、人間が創作的に関与したと認められれば、著作権が発生する余地があります。例えば以下の場合です。
- 詳細で長大なプロンプトを試行錯誤して入力した
- 数百枚生成した中から厳選し、特定の意図を持って組み合わせた
- 生成された画像に対して、Photoshopなどで大幅な加筆・修正を行った
企業として自社のAI生成物を資産として守りたい場合は、プロンプトの履歴や修正の過程(ログ)をしっかりと保存しておくことが大切です。
【実務編】企業が策定すべき生成AI利用ガイドラインの5つのポイント

リスクを理解した上で、企業はどのようにAIを活用すべきでしょうか。DX担当者が社内ガイドラインを策定する際に盛り込むべき、5つの実務的なポイントをまとめました。
① 入力データの制限(機密情報・個人情報・他人の著作物)
最も基本的なルールです。AIに入力する情報(プロンプトやアップロードファイル)に、以下のものを含めないように定めます。
- 機密情報: 未発表の新製品情報、顧客リスト、社内会議の議事録など
- 個人情報: 社員や顧客の名前、住所など
- 他人の著作物: 許可を得ていない他社の文章、画像、コードなど
特に、入力データがAIの学習に使われる設定になっていると、情報漏洩に繋がる恐れがあります。企業版の契約を結び、「学習に使わない」設定になっているかを確認しましょう。
例えば、exaBase 生成AIのように、入力データが学習に利用されず、セキュリティ機能が充実している法人向けサービスの導入も有効な対策です。

\国内シェアNo.1 自社専用のChatGPT/
「exaBase生成AI」の資料はこちらから
② プロンプト入力時の禁止事項
著作権侵害を防ぐために、プロンプト入力における禁止事項を明確にします。
- 「〇〇(特定のアニメキャラ)を描いて」といった具体的な名称の入力禁止
- 「〇〇(特定の作家)風のタッチで」といった指示の禁止(作家名を指定すること自体が依拠性の証拠になり得るため)
- 既存の画像を読み込ませて類似画像を生成する機能を使用する際は、権利者の許諾がある画像のみとする
③ 生成物の類似性チェック(検索・調査)
AIで生成したコンテンツを社外公開(Webサイト、SNS、広告、販促物など)する場合、既存の著作物に似ていないかを確認するフローを設けます。
- 画像の場合: Google画像検索などを使い、類似した画像が存在しないかチェックする。
- 文章の場合: コピペチェックツールなどを活用し、既存記事との一致率を確認する。
特に商用利用の場合は、担当者レベルだけでなく、上長や広報・法務担当者によるダブルチェックを必須にすることをお勧めします。
④ 権利の所在確認・ツール選定
使用する生成AIツールの利用規約を必ず確認しましょう。
- 商用利用が許可されていますか?
- 生成物の権利はユーザーに帰属しますか?
また、リスクを低減するためには、学習データの透明性が高いツールを選ぶのも一つの手です。例えば、Adobe Fireflyは著作権的にクリーンな画像のみで学習を行っているとされており、法人向けサービス利用時の補償制度なども提供されています。

⑤ 生成物であることの明示(透かし・表記)
必須ではありませんが、透明性を高めるために、AIで生成したコンテンツにはその旨を明記することを推奨する企業が増えています。
誤情報(フェイクニュース)の拡散を防ぐためにも、特に写実的な画像やニュース性の高い文章については、「AIにより生成」といった表記を行う運用ルールを検討しましょう。
まとめ
生成AIの著作権問題は、技術の進化とともに法解釈も変化していく過渡期にあります。しかし、現時点でも「開発・学習段階」と「生成・利用段階」の違いを理解し、適切なガイドラインを設けることで、リスクは大幅に低減できます。
重要なポイント
- 開発・学習: 原則OKだが、享受目的がある場合などはNG。
- 生成・利用: 人間の創作と同じく「類似性」「依拠性」があれば侵害になる。
- 対策: プロンプトに特定作品名を入れない、生成物の類似性チェックを行う、学習利用されないセキュアなツールを使う。
リスクを「ゼロ」にすることは難しいですが、それを恐れてAI活用を止めてしまうのは、企業の競争力を失うことにもなりかねません。正しい知識とルール武装で、安全なDX推進を目指しましょう。



