Golden Dataを使ったRAG回答精度改善のPDCAサイクル

RAG(検索による拡張生成)を活用したシステムの開発に取り組む企業が増えています。当社でもさまざまなお客さまとのプロジェクトでRAGの構築・運用を行っており、 精度改善や業務成果につなげるためのノウハウの蓄積が進んでいます。
Difyに代表されるSaaS型のRAGプロダクトが増えていることもあり、シンプルなRAG開発の敷居は下がっています。一方で、RAGの構築と継続的な運用への投資に見合う成果を得る上では業務利用できる水準へと回答品質を高め、維持することに課題感を覚えているお客様がよくいらっしゃいます。
建設系・DX部門
「開発部門内で事業部が利用するRAGを作っているがチューニングをして回答精度を高めたつもりでも事業部門からは『うまく回答が生成されない』『テストのときよりもパフォーマンスが下がっているように感じられる』といった声が上がってしまっている」
金融系・ガバナンス担当
「RAGの性質上、データの追加を頻繁に行うが過去にチューニングして改善した結果を壊してしまうことがあり、どのようにアプローチしたら良いか悩ましい。さまざまなコンポーネントやデータの変更がRAGの文章生成に影響を与えるのでイタチごっこのように感じられる」
エクサウィザーズではRAGの継続的な回答品質・精度の改善のPDCAサイクルアプローチとして、RAGに本来出力してほしい「Golden Data」と呼ばれる正解データを利用した運用を重視しています。この記事ではGolden Dataを活用したRAG構築・運用プロセスをモデル化し、さまざまな企業内で実践されるRAG活用上の参考情報としてご利用いただくことを目指しています。
- エンタープライズのDX/IT担当部門でRAG構築・運用を通じて事業成果を上げることを思考されている方
- 一定額の投資を行ってRAG構築を試したが精度が思うように出ず、運用フェーズに移行できずに試行錯誤されている方
- RAGの精度問題、大変ですよね
- 性能評価の強い味方 Golden Data
- Golden Dataへのアプローチ
- まとめ
RAGの精度問題、大変ですよね
RAG開発にかかわっている人であればRAGが生成する回答の精度にまつわる問題は避けて通れない課題ではないでしょうか。わたしたちが開発しているRAGOpsテンプレートでもChunkingのオプションを多様化させたり、Retriever/Generatorに関連する機能を充実させるなど精度改善に役立つ機能の拡充を行っています。
一方で、RAGは短期記憶と表現されることもあるように利用される知識が運用を通じて更新をされていきます。そうした変更を経てもRAGシステムを一貫して評価していくための仕組みがないと運用をしているうちにRAGの精度が下がって品質基準を満たせなくなってしまうだけでなく、精度を上げるための打ち手の検討の幅も狭くなってしまいます。こうした課題へのアプローチとして、今回はGolden Dataを利用したPDCAサイクルの構築ステップをご紹介します。
性能評価の強い味方 Golden Data
ピン留めされた評価基準の必要性
RAGをチューニングしてシステム全体として改善されたかを知るためには一貫した評価基準が必要でGolden Dataはそのためのデータセットです。こうした評価基準を持たないと、RAGを改修する際に正しく生成されていた回答に悪影響がなかったかどうか、全体としてよくなったかどうかを客観的に知ることができなくなってしまいます。
Golden Dataは評価機能へ入力することで一括してテストを実行でき、システムに変更を加えた際に品質がどう変わったかを容易に把握できます。

Golden Dataを開発者がつくるのはむずかしい
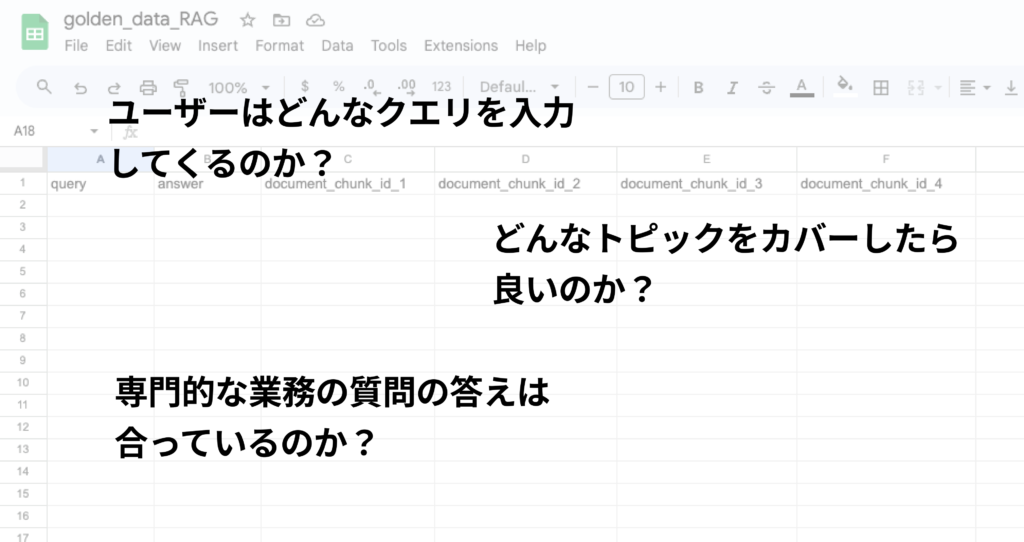
(保険会社で営業職員向けRAGのGolden Dataをつくってみる)
Golden Dataを作成する手順の例として、生命保険会社が営業職員向けに自社の保険商品の知識を持ったチャットボットRAGの開発をケースに考えてみましょう。
開発を推進するIT/DX部門の担当者は営業職員向けのマニュアルや商品のパンフレットの知識を持ったRAGを作ります。そこでGolden Dataを作ってみようとするのですがこんな問題が発生します。
(1) ユーザーがどのようなクエリを入力してくるのかがわからない
→ ユーザーとの関わりがないため、ユーザーの知りたいことをリアルに想像ができない
(2) 対象とする業務の範囲や網羅すべき知識のスコープがあいまいでどこまでをカバーすべきかわからず手が止まってしまう
→ 商品の説明だけができれば良いのか、契約の手続きに関することなどユーザーがかかわる一連の業務のどこまでをカバーしたら良いのか
(3) ユーザーからのある問い合わせに対する適切な答えやRAGの回答生成に利用すべきデータ・ドキュメントがわからない
→「新しいがん保険では上皮内新生物も保障されるのか?」といった専門的な知識を問う質問に自信を持って答えられない
Golden Dataの運用のポイント:Human-in-the-loop
RAGシステムはチャットボットのアプリケーションに組み込まれるケースが多くあります。チャットボットはユーザーの入力の自由度が高く幅広いトピックや具体的なものから抽象度が高いものまで多様なクエリが入力されます。あるトピックにおけるユーザーの知識に対するニーズを理解せずには適切な評価ができないためRAG運用においてユーザー理解は重要です。
また、RAG開発を担うのはしばしば社内のIT/DX担当部門や外部ベンダーでRAGがスコープとする業務理解が十分ではないことがあります。取り扱うドキュメントの量がそこまで多くなければドキュメントを読んで理解して対応することも可能ですが、RAG開発プロジェクトでは1000個を超えるドキュメントファイルを取り扱うことも珍しくないため、業務知識を持った人材の巻き込みがカギとなります。
Golden DataはRAGの運用と並行してメンテナンスする必要があるため、ユーザーと業務の専門家を継続的に巻き込むオペレーションをつくることになります。こうした継続的な巻き込みによりRAGを賢くしていくコンセプトをHuman-in-the-loopと呼んでいます。
Golden Data作成の実践アプローチ
手元にあるデータから初版をつくってボトムアップにスタートさせる
Human-in-the-loopを実践するにはユーザーが使う→データの不足やあやまりに気づく→修正する→…という順番をたどります。わたしたちがおすすめするのは仮説的なGolden Dataを作って検証したRAGをすばやくリリースすることです。
このアプローチでGolden Dataの初期構築に利用しやすいのが過去のログからLLMを利用する方法です。社内向けのナレッジであれば、たとえばTeams/Slackのようなグループウェア上の会話であったり、メールでのやり取りの記録からFAQのデータセットを作り出すことができます。過去に実際のユーザーから発せられている質問や問い合わせをソースにすることで、RAG上のクエリに含まれるニーズを踏襲した内容にすることができます。
 (RAGOpsテンプレートのGolden Data作成支援機能)
(RAGOpsテンプレートのGolden Data作成支援機能)
こうした方法を最大限活用して可能であれば50-100サンプル程度を目指して作成します。ただし、あくまで最初に作るGolden Dataは仮説のようなものなので今後の継続的な運用を通じて品質を高めていくための土台として考えてください。もし可能であれば実際のユーザーや対象とする業務に詳しい方にレビューをしてもらいブラッシュアップをします。
Golden Dataの構築ができたら評価機能に入力してRAGの性能を評価し、検索や文章生成のチューニングを行います。
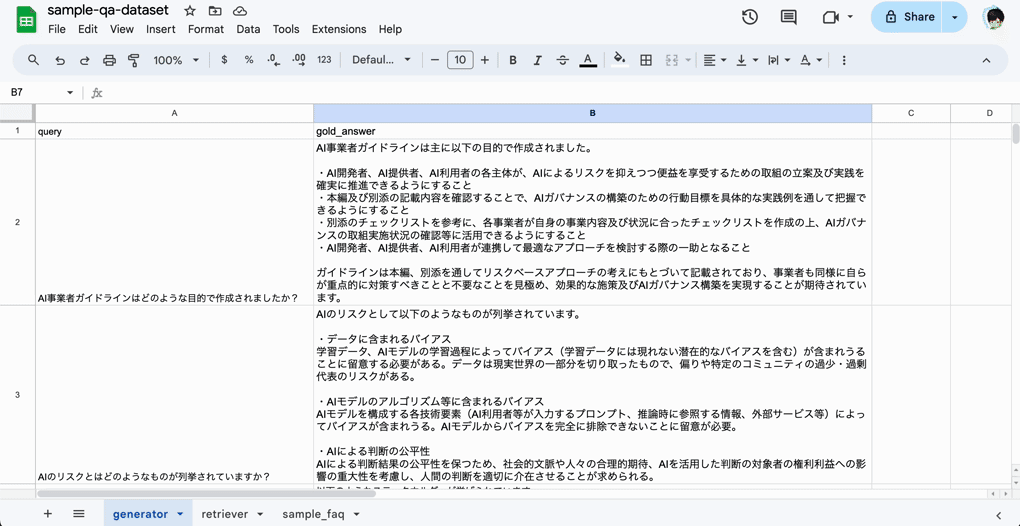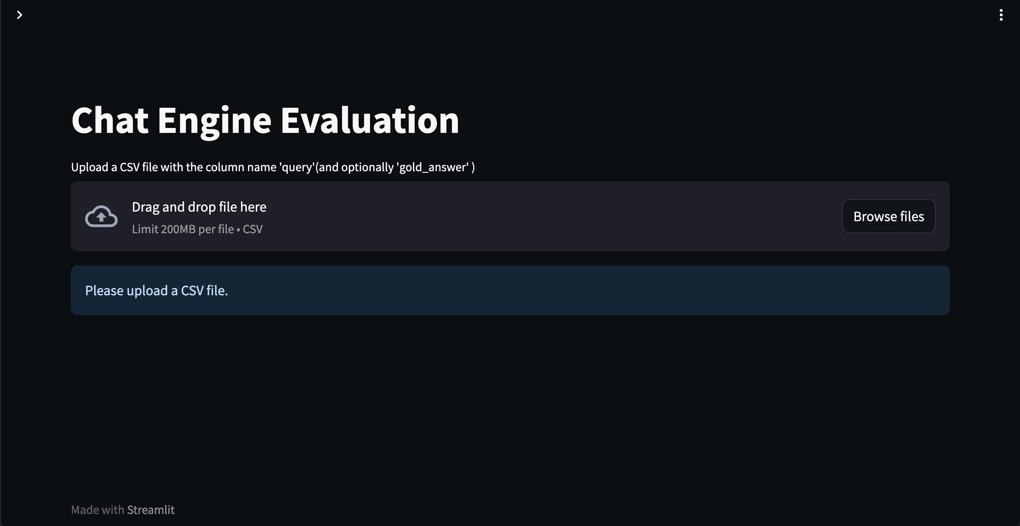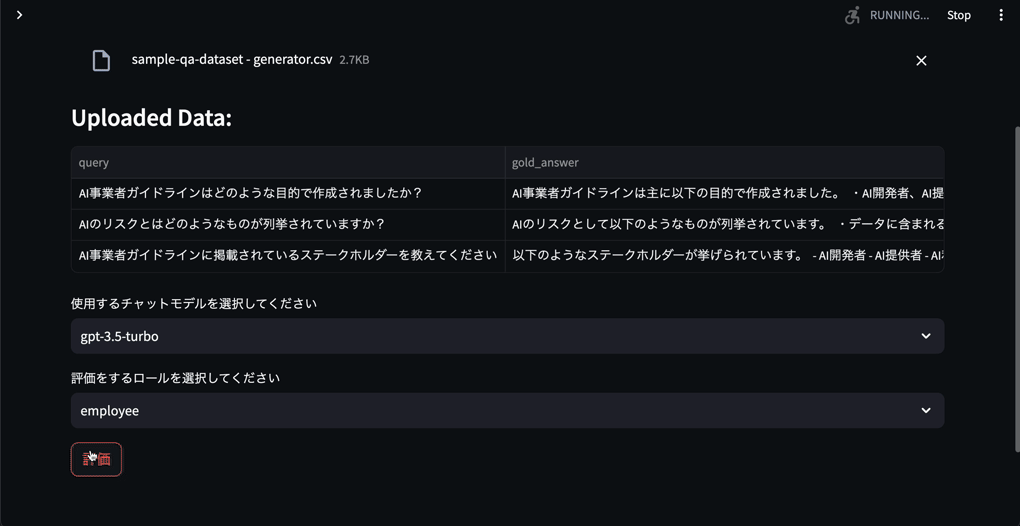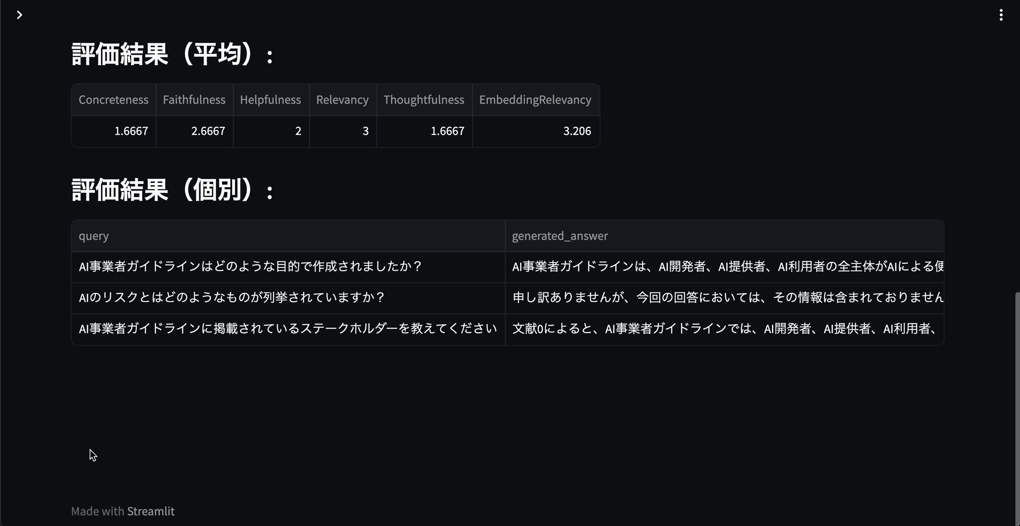 (RAGOpsテンプレートのGolden Dataを利用したGeneratorの評価機能)
(RAGOpsテンプレートのGolden Dataを利用したGeneratorの評価機能)
Human-in-the-loopでGolden Dataを磨き込む
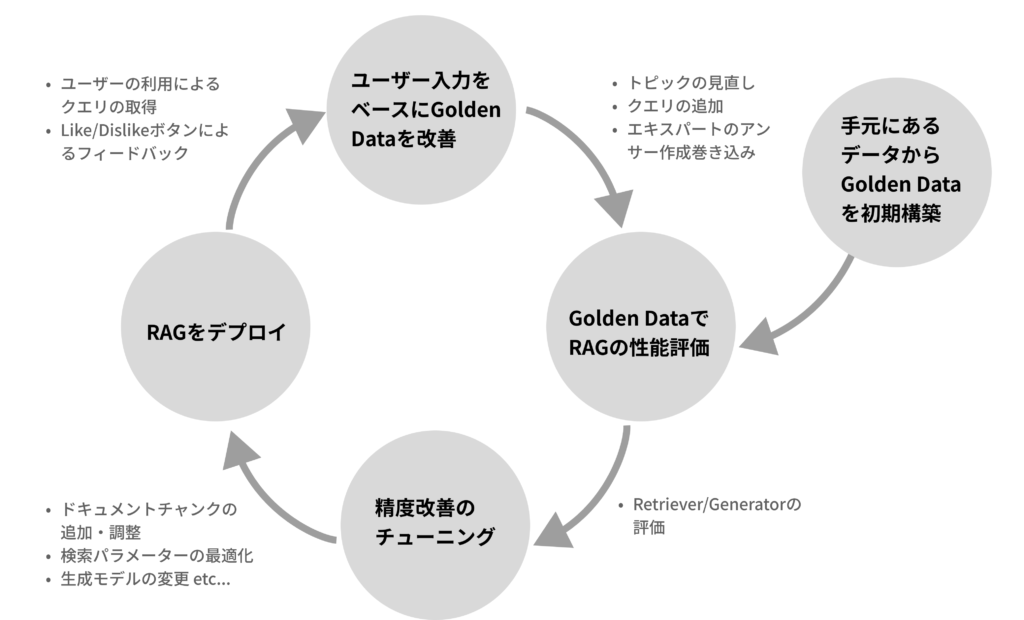 (Human-in-the-loopを利用したRAG改善サイクル)
(Human-in-the-loopを利用したRAG改善サイクル)
RAGのチューニングが完了したらリリースをしてユーザーに使ってもらうフェーズに入ります。ここからは実際のユーザーからのフィードバックをベースにトピックやクエリを調整しながら業務部門のメンバーや業務に詳しいエキスパートを巻き込んでGolden Dataを継続的にメンテナンスしていきましょう。Golden Dataが磨き込まれるとRAGの回答品質を継続的に改善するPDCAサイクルが回しやすくなります。
PDCAサイクル実践のポイント
- 実際のユーザーのクエリがGolden Dataの改善にもっとも役に立ちます。
- リリースしたタイミングがユーザーの関心が高いため、不満が上がっても素早く対応して改善がみられるとより協力的なユーザーを獲得できます。もし最初の改善サイクルに時間がかかる見込みなら公開する対象のユーザーを限定して改善をしながら公開範囲を広げる方法も有効です。
- 前述のようにRAGシステムを構築する担当者とドメインエキスパートと呼ばれるRAGが対象とする業務領域の担当者は異なることが多く、正しい知識をGolden DataやRAGのデータセットに蓄積していく上ではエキスパートの巻き込みが必要です。
- あるひとつのRAGシステムのスコープにおいて複数のエキスパートのサポートが必要になることもあり、PDCAサイクルを進める中で適宜エキスパートにサポートを依頼するための機能もRAGシステムのオペレーション機能として備えておくことが望ましいです。
まとめ
今回はGolden Dataを用いたRAGの精度改善PDCAサイクルについてご説明しました。
特に実践上のポイントとなるのは以下のふたつです。
- 手元のデータからはじめる:Golden Dataは利用可能な過去のログ等から作成し、運用を通じてインクリメンタルに品質を高める
- Human-in-the-loopの実践:ユーザー・エキスパートを巻き込むことで組織的にRAGの回答品質を改善させるオペレーションを作る
RAGの導入は業務の自動化にとどまらず、組織全体の業務設計やナレッジマネジメントをAI/LLM時代に最適化させることで、AIの持つ可能性を最大限に引き出す組織改革にもつながると言えるかもしれません。RAGを用いて現場業務を変革していく取り組みは従来のシステム開発よりも一層現場業務の理解が求められる上に、システムが果たす役割もインクリメンタルに変化させていくあり方が求められます。今回ご紹介したPDCAのあり方がそうした歩みの一助となれば幸いです。
エクサウィザーズが提供するRAGOpsテンプレートではGolden Dataを活用したRAGのPDCAサイクルを実現するための機能を備えています。オペレーション構築やRAG活用プロダクトの企画〜開発を一気通貫でご支援するプロフェッショナルサービスもご提供しておりますのでRAG構築・運用のご相談やお問い合わせをお待ちしております。
RAGOpsテンプレートのお問い合わせ
RAGOpsテンプレートに関するより詳しいご案内をお求めのお客様は、下記よりお問い合わせ下さい。