エクサウィザーズ、画像の着目点を対話型で説明する 生成AIモデル「exaBase Visual QA」を開発
〜画像内の危険や異常を高精度に解釈、学習済みで商用利用も可能〜
株式会社エクサウィザーズ(東京都港区、代表取締役社長:春田 真、以下エクサウィザーズ)は、画像の内容を基に、その状況を対話型で説明する生成AIモデル「exaBase Visual QA」を開発したことをお知らせします。一般的な生成AIモデルに比べて、画像内の危険性などの状況を高精度に解釈して説明文を生成できるのが特徴です。消費者向けのサービスなどの商用にも利用可能です。
エクサウィザーズはAIの利活用によりサービスやプロダクトを提供し、それらを通じて生産性向上や社会課題の解決を目指しています。

☑︎開発した生成AIモデル「exaBase Visual QA」の特徴や利点
画像を認識する一般的な生成AIモデルでは、特に複雑な画像についてその危険性などの内容を的確に文字情報として出力するのが難しいとされています。そこでエクサウィザーズは、人が画像を見た時にどこに注目するのかを生成AIモデルに学習させることに取り組みました。
結果として、人が直感的に認識可能な、画像内の危険性や違和感といった状況を高精度で解釈することが可能になりました。exaBase Visual QAを実装したシステムとチャットボットのように対話することで、状況を説明する文章を生成します。
具体的には以下のような画像に対して「潜在的な危険性はありますか」と入力することで、「作業員がバランスを崩したり足場が崩れたりすると落下につながる。作業員は金属棒を接続するために電動工具を使用しており、工具が滑ると負傷する可能性がある。適切な安全予防措置を講じるべきである」といった文章を生成します。
システムの実装時には長文を出力しますが、それらをChatGPTを用いて必要な部分にフォーカスした要約が可能です。
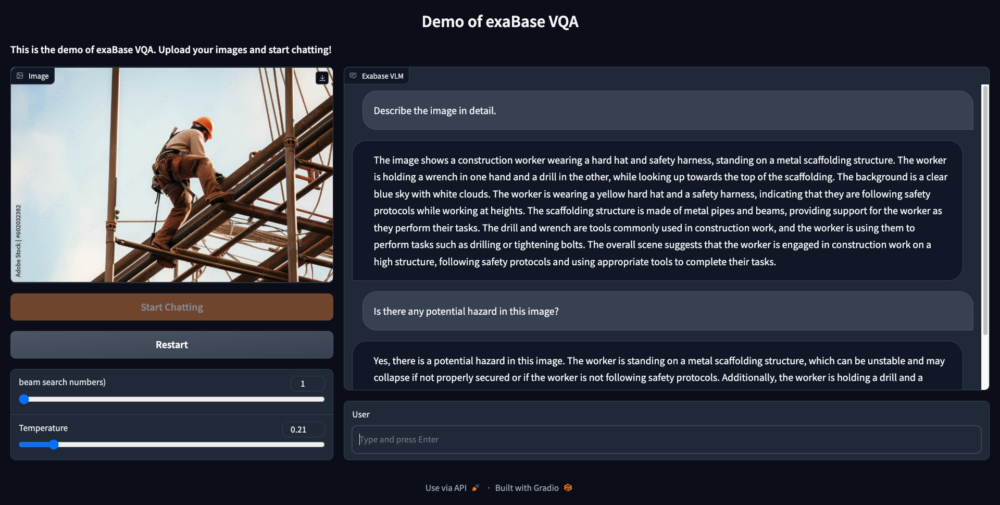
画面 exaBase Visual QAのプロトタイプ画面(現時点で文章の入出力は英語ですが、翻訳機能を利用することで各国語に対応できます)
なお当社での評価実験において、他の商用利用可能なモデルより最大で1割弱高い解釈の精度を持っていることを確認しています。同様の精度のモデルと比べてモデルのサイズも小さく、推論の実行や生成の速度も高速です。
exaBase Visual QAはオープンソースの生成AIモデルをベースに開発しており、当社が追加学習を実施しているためすぐに利用が可能です。さらに個別の分野のデータを学習し、設定を調節する「ファインチューニング」を当社側で行うことで、特定の分野での精度を向上させることも可能です。
☑︎適用分野 〜幅広い分野に適用可能、分類モデルとしても活用も〜
exaBase Visual QAは自由な質問が可能で、幅広い分野の画像に対応可能です。特に自然画像(人工的に生成した画像など以外)は高い精度で解釈できます。解釈した意味内容に基づいてデータを振り分ける「分類モデル」としての利用も可能です。
・建設現場などでの作業における危険性の判定
・保育園や学校など、多様な人の動きがある場所での状況把握
・様々な対象における、故障場所の把握や内容分析
・カメラやセンサーなどの画像に対する、事件や事故の把握
・大量動画の文章化、特定の場面を抜き出すことでのデータ圧縮
・製品ラインなどで、合否を判定する分類モデルの構築
☑︎提供形態 〜静止画のほか動画でも利用可能に〜
今回開発したexaBase Visual QAは生成AIモデルであり、さまざまなソフトウェアやシステムに組み込んで活用することを想定しています。現時点でPoC(概念実証)用途でのご提供が可能です。当初は静止画を対象としますが、動画での活用も可能です。
【株式会社エクサウィザーズ 会社概要】
会社名 :株式会社エクサウィザーズ(証券コード4259)
所在地 :東京都港区東新橋1丁目9−2 汐留住友ビル 21階
設立 :2016年2月
代表者 :代表取締役社長 春田 真
事業内容:AIを利活用したサービス開発による産業革新と社会課題の解決
URL:https://exawizards.com/
<広報に関するお問い合わせ先>
株式会社エクサウィザーズ 広報部 メール:publicrelations@exwzd.com